Loading...
Innovation, our reason for being
When a few months ago I wrote about Proxia® geographical capabilities, I introduced the problem we must address when our applications are intended to run into several nodes of the same cluster. As a matter of fact, designing and architecting an actual enterprise-type application not only is about deciding whether we are going to use micro-services or a concrete technological stack but also how our application is going to cope with heavy load, or an increasing number of users. Obviously, the answer is horizontal scaling, just adding more servers to a cluster. But do these nodes are completely autonomous? Do they have to share information? Do they need to send and receive messages, or is it only a shared cache problem?
In my opinion when we talk about clustering, we are really talking about messaging problems. You could argue that in a typical cluster environment you need to share information and state between different nodes, so it’s a shared cache problem! Let’s analyse it a bit deeper.
First of all, if your application needs to store information in a cache system, it needs it whether it executes on a single server or in a cluster. A cache is used to improve database roundtrips, or to memory-persist state for a later stage. Hence, when you scale your application horizontally what your local cache needs to solve is how to support distributed cache issues, how to communicate an expiration or a renewal to name but a few. In fact, these are not related to storage but to communication, messaging.
Furthermore, sometimes what your system needs is only messaging capabilities. Let’s imagine that your application is a websocket-powered one. When you horizontally scale your application, how are you going to solve communication between end-users, one-to-one or broadcast, between different servers? Is this really a cache problem, or just a messaging problem between the different nodes in the cluster?
There are several solutions to solve this problem, but in this post, I’m going to tell you how we are working at Divisa iT.
When designing a messaging system, there are several problems that could arise, are all nodes alive? Are they responding properly to requests? How can I detect whether a node goes down or up? How do I discover new nodes? How do I identify a node? Are all nodes running the same codebase? Am I going to provide any fallback solution?
Besides these internal system problems, there are also external ones, mainly those related to system extensibility, or better addressed as making easier developers’ adoption.
First of all, when we designed our system, we wanted it not only to be self-controlled but also to allow external management from a central console. Although there were different solutions, we wanted to support standard functionalities – or at least standard in those days – so we decided to use JMX, allowing us to execute management operations from JConsole or an SNMP control panel.
Using JMX stack provided us with solutions to some of the previously identified problems, as node identifier, but many of them are out of the scope of JMX core services, so we had to take decisions,
Nonetheless, there were many other problems to be solved. The solution involves a state machine, as shown in the following picture.
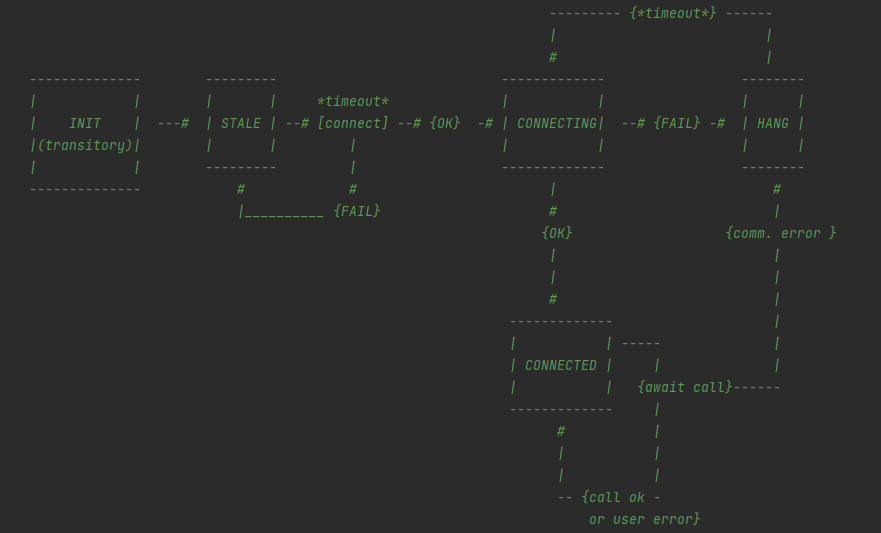
Using this state machine, allows us to detect:
Generally, when you want to improve any system adoption you need to focus on different use-cases, providing both general approaches and particular ones when you have very limited and repeated issues.
Considering the problem, we decided to provide a dual solution. On the one hand a subsystem intended for global messaging problems, and, on the other hand, a subsystem limited to cache usage. Latter one uses the same messaging system under the hood but provides an opinionated layer on top on it.
Nonetheless, both systems are built using Java annotation features, you can see my previous post if you are interested in how we use them at Divisa iT.
Cache subsystem
Cache subsystem usage is quite straightforward from a developer point of view, we just need to annotate our class.
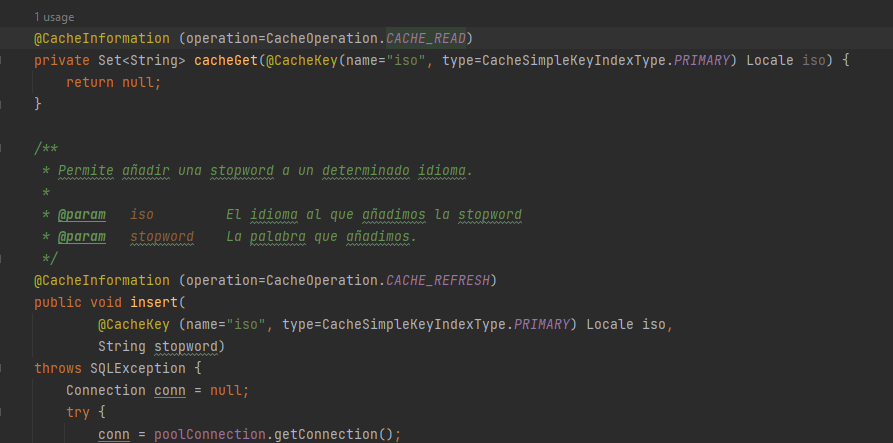
And magic is performed under the hood, with the aid of some ASM.
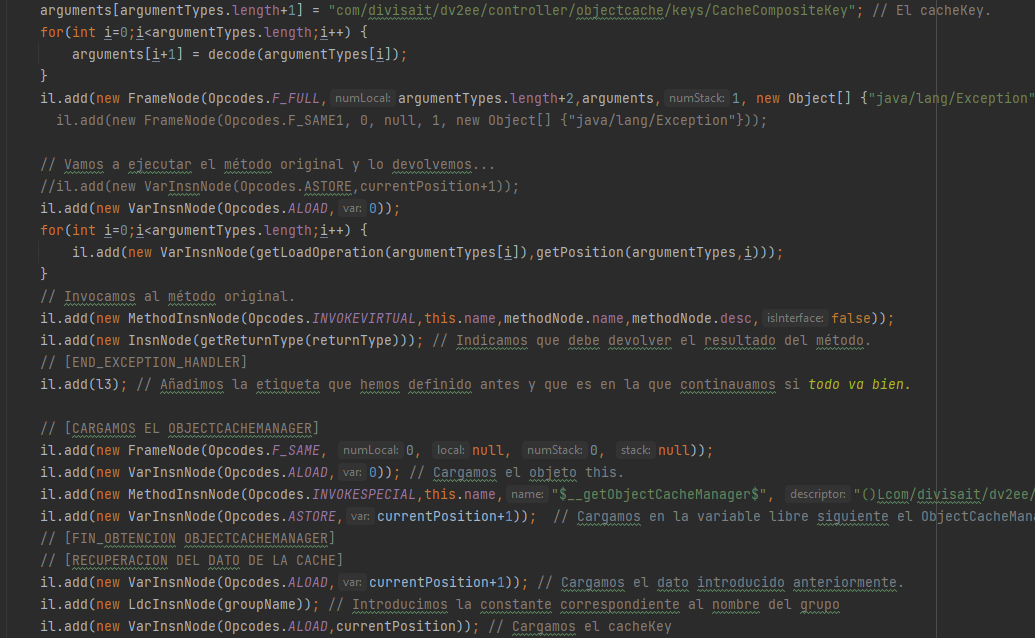
I’m not going to enter into deeper details, since I’ll spoke about our cache system in a future post.
Global messaging subsystem is more complex to use, and we differentiate between server implementation, which is done as shown in following picture.
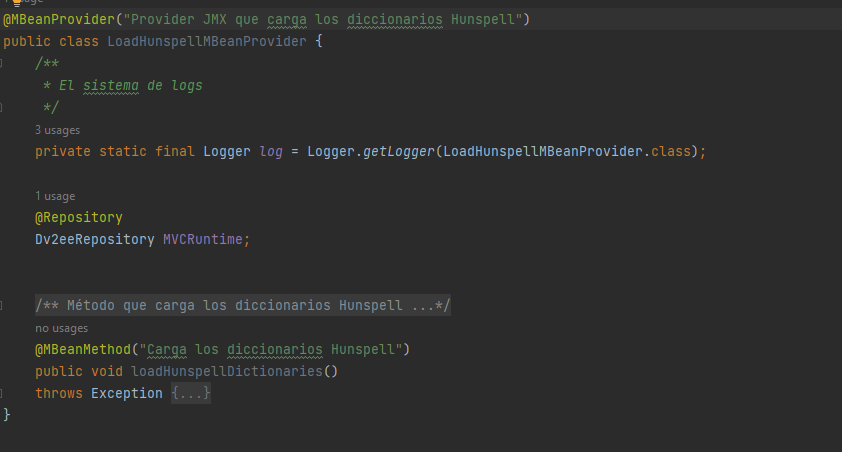
And client implementation, which is a bit harder to use since, now, we aren’t creating any stub to simplify its utilization.

As a matter of fact, we are using it for complex tasks, not common on a day-to-day basis as, for example:
Obviously though, the process of developing this solution hasn’t been straightforward. We have followed an iterative approach across the years, learning from errors, replacing big parts of the underlying implementation, providing it with a good testing system, extending to different use-cases and so on.
 David Rodríguez AlfayateTechnology, products and special software projects Manager.
David Rodríguez AlfayateTechnology, products and special software projects Manager.