Loading...
Innovation, our reason for being
Tools are just tools. Therefore and ignoring hype what we must do in order to use them properly is finding a situation not easily solved without them. Undoubtedly, 2023 has been AI year, mainly generative one. Surely, you’d have heard about, or even used, its image or code generation capabilities not to mention its natural language features to name but a few. But, when we think in actual client problems, the ones typical solved by engineering, things change a bit.
As a matter of fact, actual client problems are not about chatting or generating an image, but about embedding some of those functionalities in a more complex system. Therefore you could think in AI usage as a typical software subsystem, as a cog in a bigger mechanism.
Hence, I’d like to focus on different AI scenarios that we have used in Divisa iT products and projects along this year. All of them are targeted to solve different issues, but sharing the subsystem approach previously mentioned.
One of the most typical software system that I could think on is the one that involve end user data. Let’s think about a very simple problem, text introduction, not only should we ignore text with swear words, but insulting one or even extremely negative one. Performing a manual review could be tough and time consuming.
Besides text, our end user could also upload images. If we don’t filter images we could include copyrighted material, pornographic one or, apparently less important, anonymous citizen faces. Logically a disclaimer is not enough when dealing with this data, and our client could have a serious problem if we don’t prevent it.
Obviously we could prevent this kind of information to be published publicly. But certainly there are situations in which this publication could be desirable, and I’m not talking about a social network, but about management applications in which we want to reinforce transparency. Imagine a complaint management system, wouldn’t you want to publish the maintenance state of a bench or a bin as uploaded by citizens? Wouldn’t we like to make this upload in an anonymous way?
If you think about it, you could note that there a lot of potential issues, and managing them manually could probably drive to not publishing any image at all. Here’s when AI comes handy. We could erase pornographic image, or delete anonymous citizen faces.
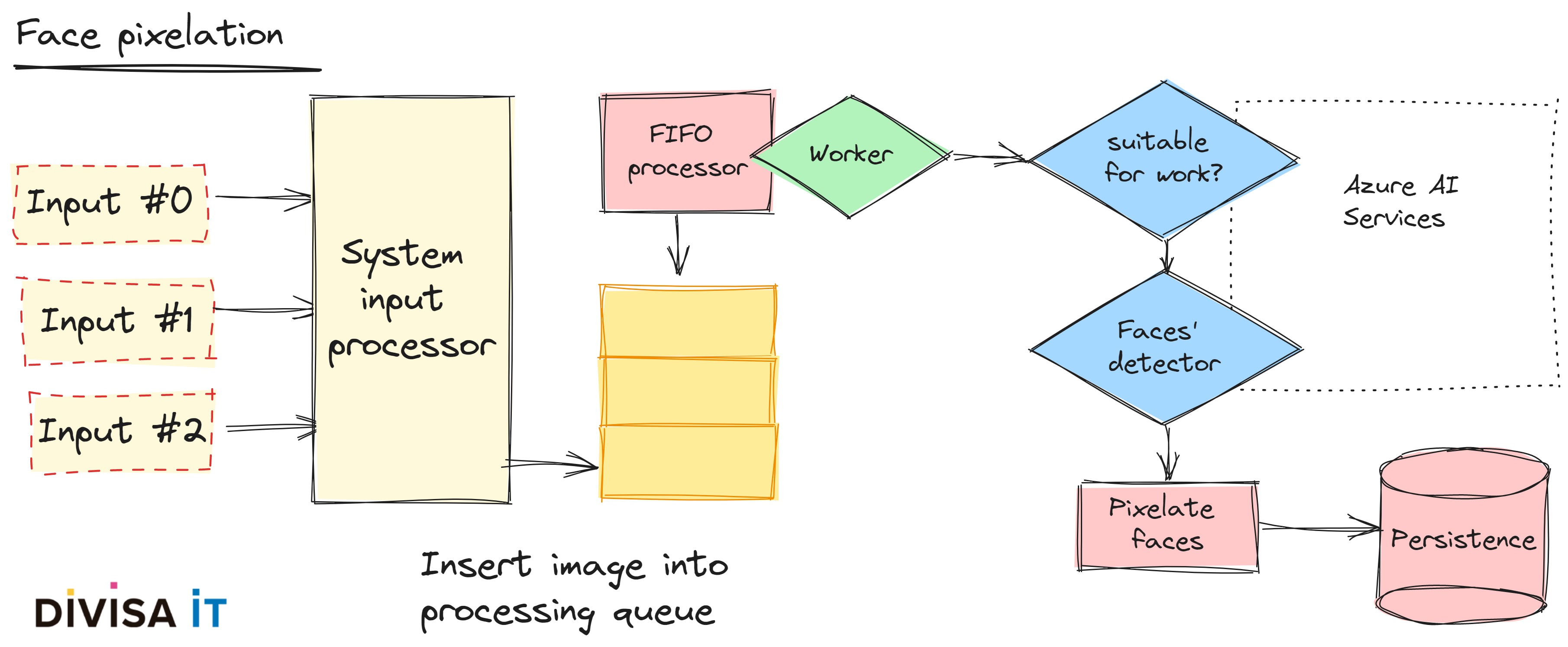
But from an engineering point of view, which is my main concern, what should we take into account?
When you develop applications there are some typical problems that you have to face. Is your application going to support only one input channel or are there going to be several? The latter case is certainly problematic, since each channel will impose its own dialog flow.
Let’s focus on a simple scenario in which end user could introduce data using a guided form, you will have some input options, perhaps a selector and probably a textarea. Let’s change it a bit, imagine an email channel or a WhatsApp one. The first one doesn’t allow a dialog, and the second one, although you could create a bot, discourages it if you want to improve interaction, keep it simple!
Therefore, what can we do? Avoid these input channels? Is this possible or even desirable? If answer is negative, is a manual review accomplishable? Probably the answer is that our client wants to do it, but automatically. Again AI could help us, using in this case perfectly known algorithms as Naive-Bayes, provided we have enough training data.
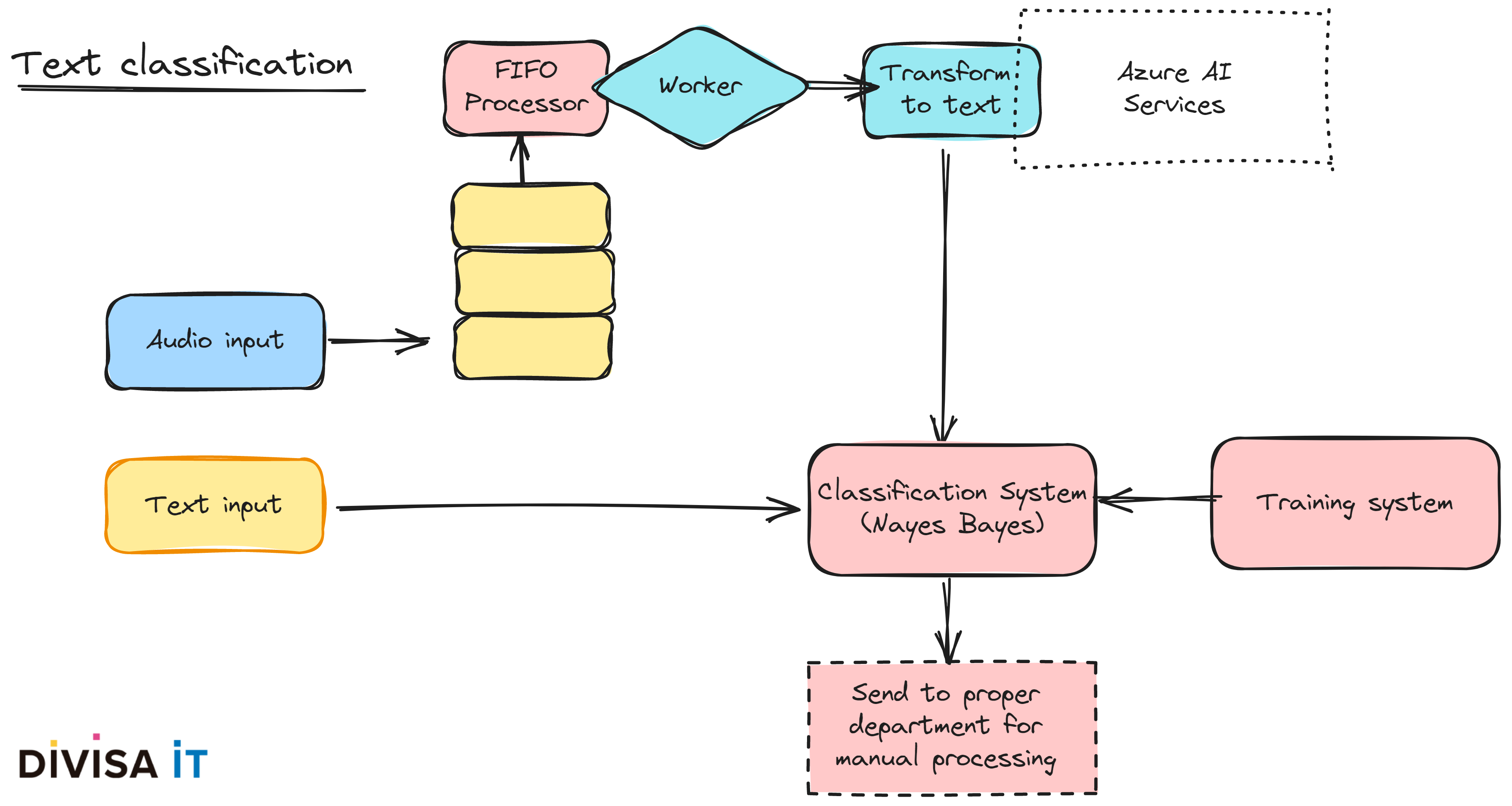
Furthermore, from an engineering point of view, there are again issues to address:
As far as I can remember, the idea of introducing an agent in a web site to make easier information retrieval has been always present. Problem solution typically involved creating a decision tree, in which questions and answers were quite stereotyped, providing a not very natural dialog.
The advent of LLM solutions, as ChatGPT, has certainly created a new way to solve this problem. In fact, it seems so human! It even lies although its lies are called hallucinations.
Let’s think about its usage in a client. What we want to do is to search in its database, in its information, in order to provide good answers. But do we want facts or perhaps invented answers? Are we going to cope with problems created by an imaginative answer to a request? Just imagine the problem we could cause if we are reporting a wrong milestone for the presentation of a paper, or not giving information about all required information that should be provided for requesting a grant.
Probably a custom training could help us minimizing these problems. But as I like to say engineering is about managing scarcity, sometimes you don’t have enough budget, other you don’t have enough time and many others you don’t have any of them.
Therefore assuming this scarcity we should find a solution which could help us tackle this problem. Can we use a pre-trained LLM, as ChatGPT? Certainly, but we must use a different approach to the "standard" one.
Let’s go deep into it. First of all, we should question ourselves what we want our agent to do, or even better what problem are we trying to solve.
Answers to these issues will define how are system will work but, typically, we will have a complex context - n-dimensional one - having a m-n relationship with our question dataset. Hence and again considering our engineering point of view we’ll have to tackle following matters
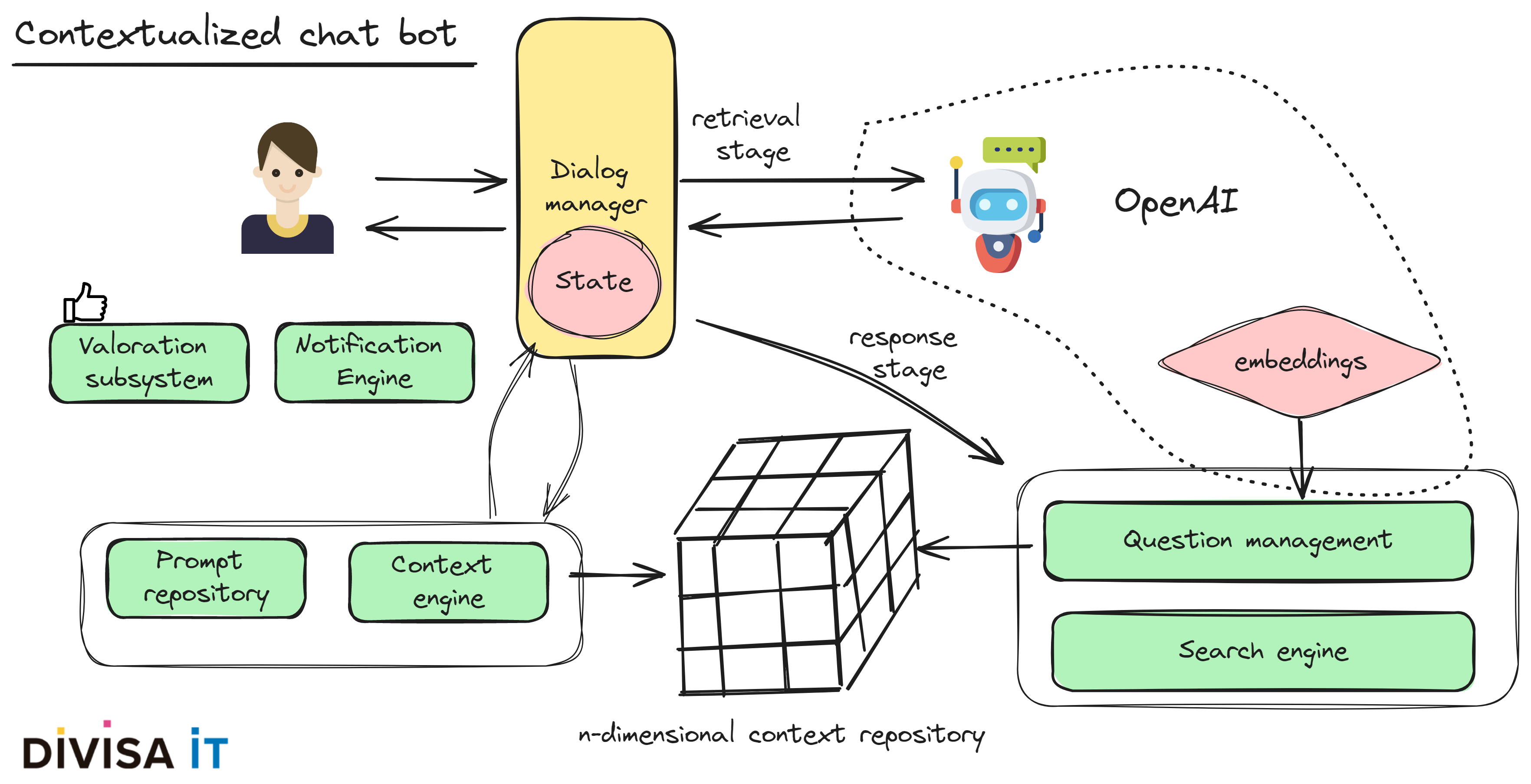
As I have tried to show using AI powered solutions could help us achieving better results, but that doesn’t neglect a proper software architecture and good engineering practices.
 David Rodríguez AlfayateTechnology, products and special software projects Manager.
David Rodríguez AlfayateTechnology, products and special software projects Manager.