Loading...
Innovation, our reason for being
In my opinion, one of the most typically forgotten problems when developing applications is offline mode. We are so used to web programming, that we have forgotten different issues that may arise when the server is not available, or the connection is not as good as it should be. As a matter of fact, these problems are not so important when our application is only web based, but you should wonder what happens when your application is, in fact, a PWA, a mobile hybrid application or even an Electron based desktop one.
Therefore, if your application is going to be one of those, you should consider how it should be developed or what are the problems that you are going to face. A first approach could be to reduce the problem to a typical producer-consumer one, nonetheless the problem is, in fact, a synchronization one, and there are other matters that should be considered as, for example, is there a single origin of truth? can different users modify the same data?
On the other hand, I’m sure that you have learnt that when you develop a synchronization process you shouldn’t perform it in the same "thread" as the rendering one. In fact, you don’t want that "painting on the screen" could suffer from high-consuming CPU processes, or complex updating problems. While this problem is quite typical and acknowledged when developing native mobile applications, perhaps you are not so used to it when your development target is the browser, and your programming language is JavaScript.
Along this post I will try to provide you with information about how this problem could be solved in JavaScript. If you are in hurry you could go directly to this Github repository where you could find a simple example and some sample code. If you want to read something more, follow me.
where you could find a simple example and some sample code. If you want to read something more, follow me.
As I stated above, the issue that I am trying to show you is a syncing producer consumer one. Think of it as an environment in which:
In a typical situation you could send data to your server, implementing whatever technology you want to sync data as long polling or web sockets to name but a few. But what does happen if your environment is a mobile one, with a slow connection or even you don’t have connection at all? Are you concerned about your end-user experience?
If your answer is affirmative, I think that the best way to solve the problem is pondering over it as if it were not server at all. Let me explain it a bit, surely you need to read information and you need to store it in a persistent way, but from your business logic application point of view you shouldn’t be concerned about server synchronization. If you know Redux, you should be comfortable with its collateral effects, if you don’t know about it, or you are not very keen on collaterality idea, think on it as if:
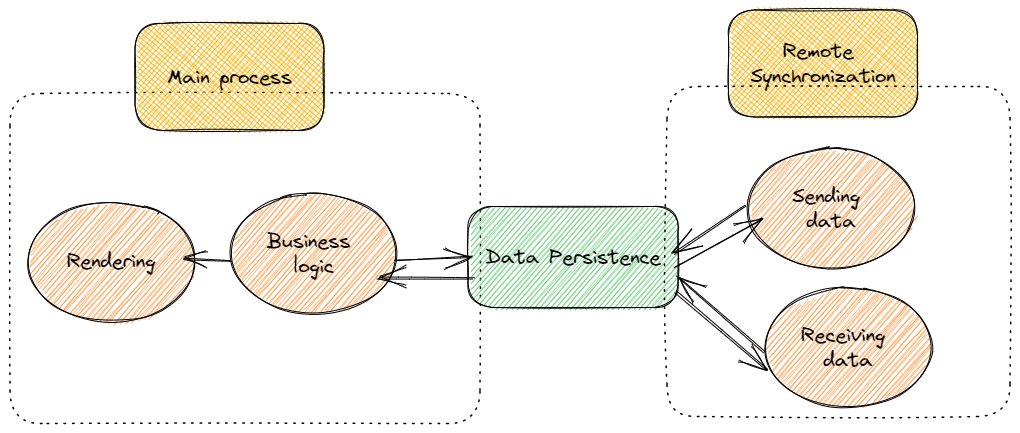
Therefore, architecting our frontend application should be focused on:
a try. to perform this functionality.The frontend logic is outside the scope of this post, is your logic! So, in the following points I’m going to analyse persistence, and queue processing using web workers. Note that there are other many complex issues that should be addressed in a end product as, for example, data security, data collision – update of same information in different application by different users – which I’m not going to cover in this example.
As I told you previously, IndexedDB comes to the rescue. Unfortunately, IndexedDB is a low level API, a bit tough to use, so if I were you, I would use some high-level APIS built on top on IndexedDB as Dexie. This is the approach that I’ve followed in the shared Github repository.
From my point of view, one of the main advantages of NoSQL storage – as IndexedDB – is that we don’t have to be aware of the actual data we are going to read or store, what we just need is to have some access mechanism which could provide us with enough information as to perform our duties. Hence the question is, what do we need?
Basically, I want to create a database unaware of actual information but that could be used to perform basic CRUD operations and queue and universal identifier storage ones. To do this, we could create a basic TypeScript class, extending Dexie model. What do we need?
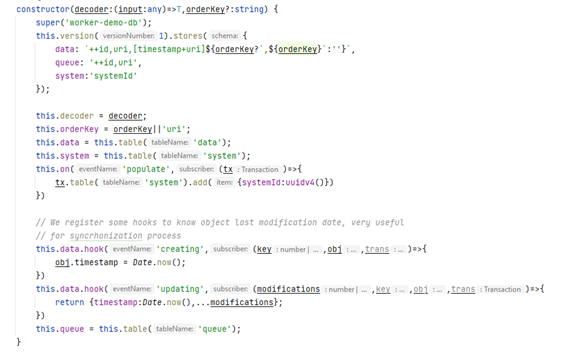
In this constructor, you can see that I’ve created three tables, note that in IndexedDB you only need to define indexes, not actual data structure.
As you can see there are some hooks which allow us to introduce the timestamp – last update date – whenever we create or update an entity.
Wait a moment, I’m talking about entities not about actual data, well that’s the magic of IndexedDB and TypeScript, we don’t have to fully define our data model, we just need to provide enough information as to be reusable.
![]()
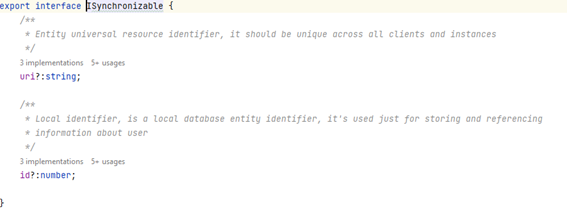
Our database code should be able to return data with the proper model using, for example, decoders, that, in my example, are passed as params to constructor and will be used when reading data.
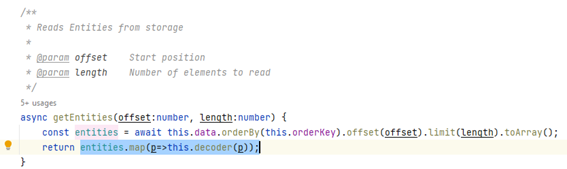
You could wonder how we manage the queue. Actually, it is a quite straightforward process, we just have to customise the creation, update and removal process.

We could have used database hooks to perform this queue modification, but it should be noticed that we want to avoid loops, we don’t want that remote synchronization could introduce an update in queue, don’t we? Obviously, there are ways to do it, but they introduce some dirty code that it’s not so easy to follow.
If we want to read or sync our data from remote server, we just need to access database and some methods intended for synchronization.
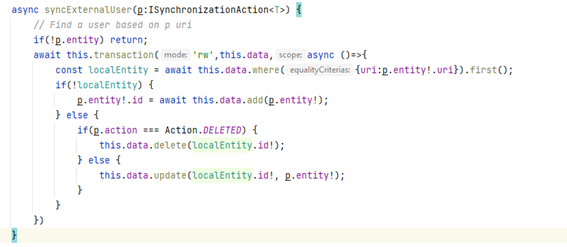
For example, this piece of code allows to apply a synchronization action on our database, deleting entries or even creating or updating them. We are always using Universal Entity Identifier instead local id.
Queue processing, on the other hand, is a bit trickier, promises could be involved (fetch request for example), we should perform – in my example – all updates sequentially avoiding further entry resending if the remote synchronization process is successful.

We are just reading the queue, getting actual information to send – except if action is a removal one – sending it to remote server and if it is successful, we are removing entry from queue. Just a side note, some JavaScript magic, since we are storing timestamp within data table this is automatically sent to our remote server, so it could be used to know whether update should be performed or not.
To make easier the access to storage we need to provide some mechanisms. Since in this example I’m using REACT, I’m going to focus on providing database access through context and custom hooks.
Creating a context allows us to create the database in a REACT way, using just a wrapper component in our application, this component is accountable for creating database and providing access to it from our application.

We are just creating a state, which holds the actual database connection, and showing our application children. As simple use case could be as the following:

Once we have created the context, we want to access it, as to read, delete or update information. We could manage it manually, but this is neither very clean nor reusable, so the best approach from a REACT point of view is creating a custom hook, which wraps all complexity in a quite simple way.
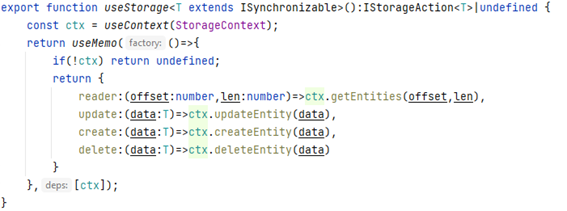
As you can note, I’m using thoroughly previously defined interface and TypeScript extension, this allows our code to be properly defined and correctly reusable. The useMemo hook allows our storage object to be used in useEffect hooks without collateral problems.
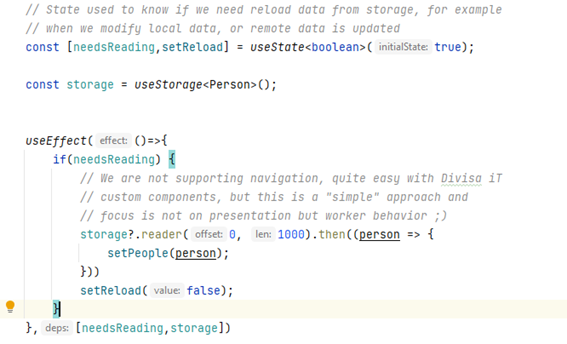
In order to perform these tasks, I’m going to use Web Workers, if you don’t know what they are, just think on them as independent processes that execute in your browser and don’t affect your rendering and application business logic. Even though I could use only one worker, I think that it’s better to create two of them:
Besides sending and receiving data, there are other needs to cover as logging or plugging in the workers in our code in a seamless way.
Just think that sending data to remote server is a repetitive process since we have to do it forever – at least while our application is alive –, so we must use some simple JavaScript utilities as timeouts, only complexity comes from using a worker.
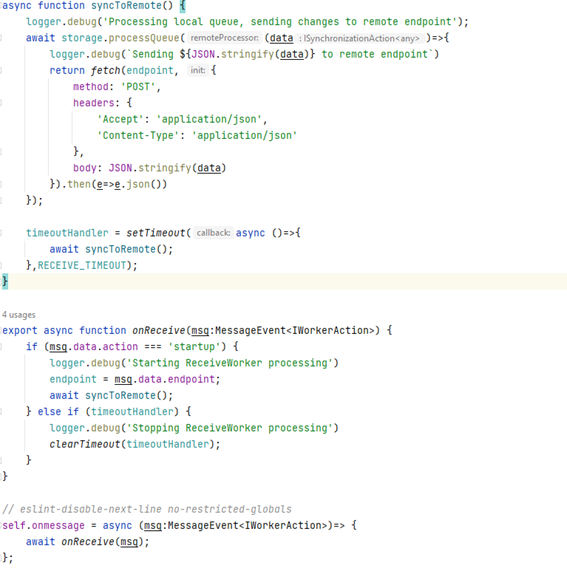
Code is quite straightforward, our syncToRemote function is very easy to follow, we are just retrieving data from database and sending it to our server using fetch API.
When designing the receiving algorithm, the first question that we should address is if we want the server to send us all information in every synchronization request. I am quite sure that your answer will be negative. If that is the case, our communication protocol should be designed taking this into account, something as shown in following picture.
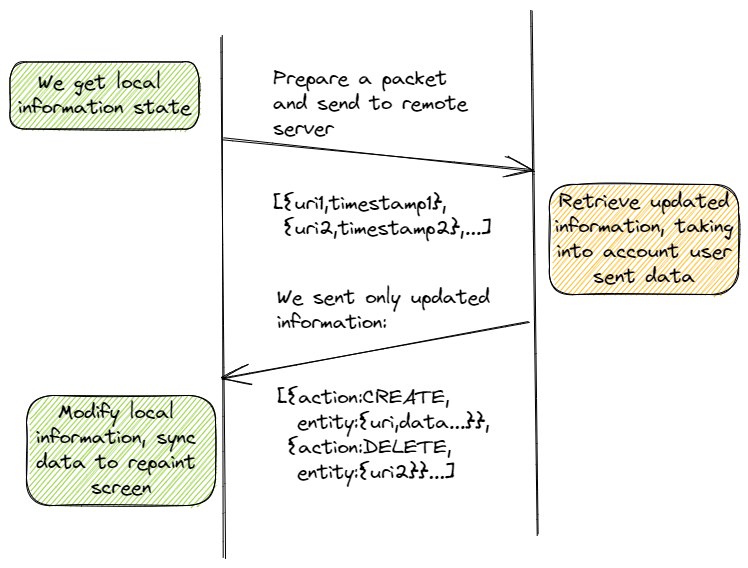
You can note that,
The sample code for this approach could be.
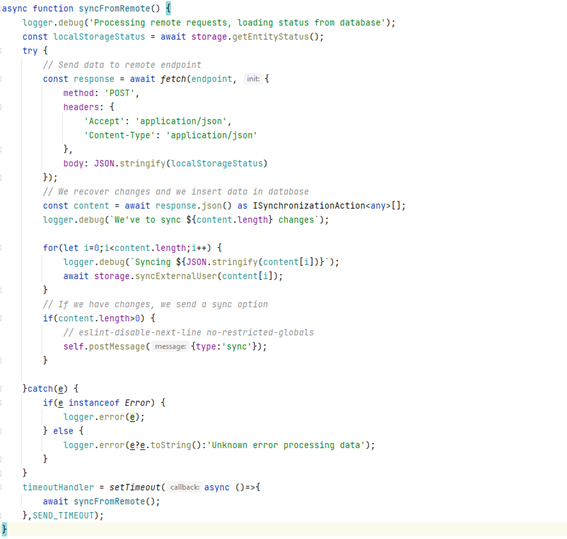
I have created a function in our storage named getEntityStatus that provides us with URI and timestamp information.
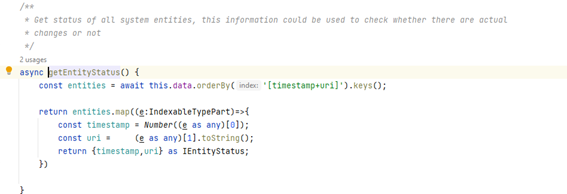
Received information is synced on our database and we use a special postMessage to inform our application logic that there are changes that should be shown to users.
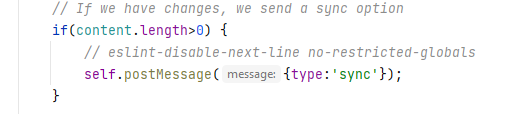
To use workers in our application I’ve decided to create a new custom hook, providing us with code reusability.

Hook creates workers – using a function but that is only for testing purposes –, implementing both startup and shutdown functions and receiving data such as logging and syncing.
Using our hook in our code is really simple, we just have to plug it in in the proper place, and send required information (logging mechanism, endpoints, and sync function to reload data shown to end-user)
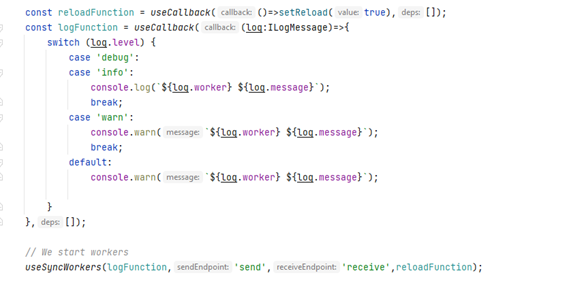
Whenever you develop an application you should provide some logging mechanism, don’t think in console, this is not going to help you to know what happens to your end-users.
Logging could involve sending data to a remote server, perhaps a sequentialization, etc. When using Web Workers you should take all these issues into account, so one good approach could be creating a Event based logger using Web Worker’s postMessage Events.
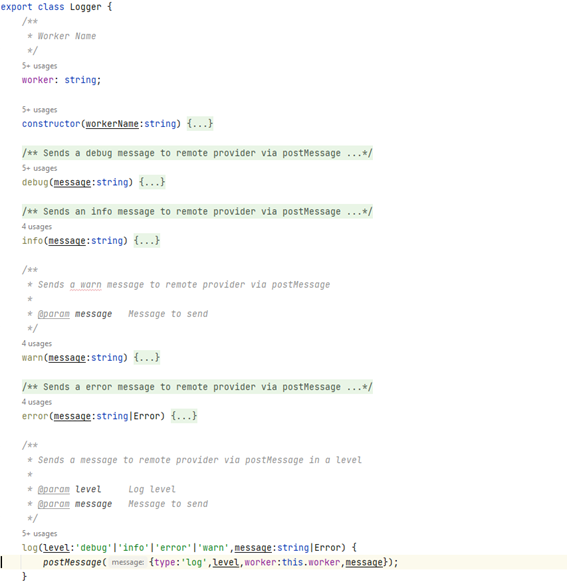
In my sample code I’ve just used a console logging mechanism, but I hope that the general idea could give you a better comprehension on how to do it properly.
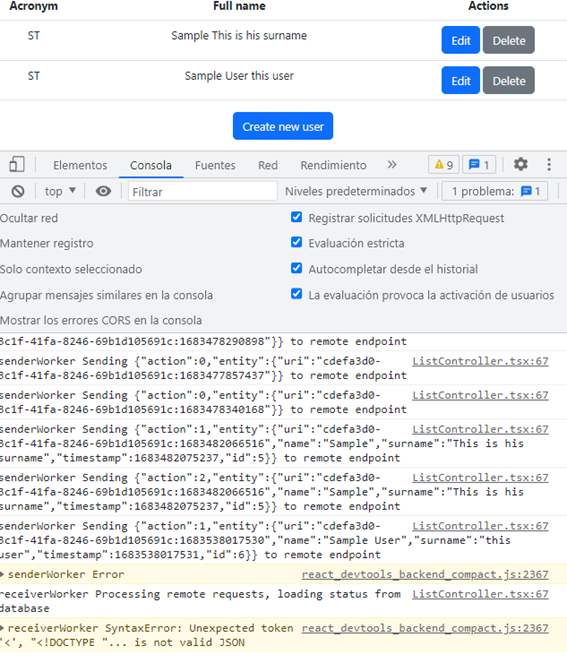
Once all the infrastructure is created we can use it from our application, in this image I show the sample application that you could download from my repo, and the errors shown in console related to unavailable remote endpoints.
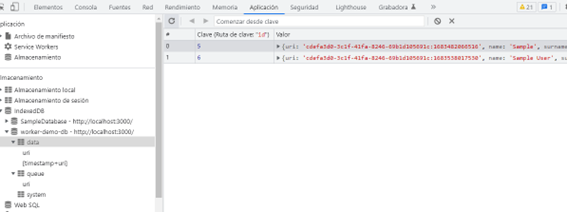
If you check IndexedDB database, you could find some valuable information about stored data, as data table:
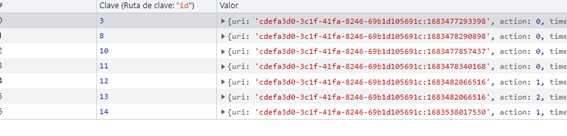
Or even the queue one,
Besides information about how workers could be used to perform synchronization, I think that you could also find some valuable information in the repo as, for example, how we should have proper models and isolate business logic from view logic, meaning that the view should only be worried about painting on screen and the business logic and routing should be placed in different components.
 David Rodríguez AlfayateTechnology, products and special software projects Manager.
David Rodríguez AlfayateTechnology, products and special software projects Manager.