Loading...
Innovation, our reason for being
Let’s face it, some tasks are CPU – or GPU – consuming, other are slow and some of them are both CPU and time-consuming. Imagine for a moment, that one of those tasks is called from a REST endpoint, do you know what problems could occur? I suppose that you could wonder why you should want to do that. I’ll tell you two little secrets. On the one hand your user will want to do whatever task would be needed from a user interface, on the other hand provided that your code performs something pretty more complex than storing data in a database or querying from it, at some point it will have to perform complex operations. Do you want some examples? Populating a database or performing an AI powered task to name but a few.
Hence, once you have agreed that there could be a possible issue, we need to analyze it. First and foremost, I suppose that you know that a HTTP server is able to attend several requests at the same time. If my tasks are CPU consuming, what is the problem?
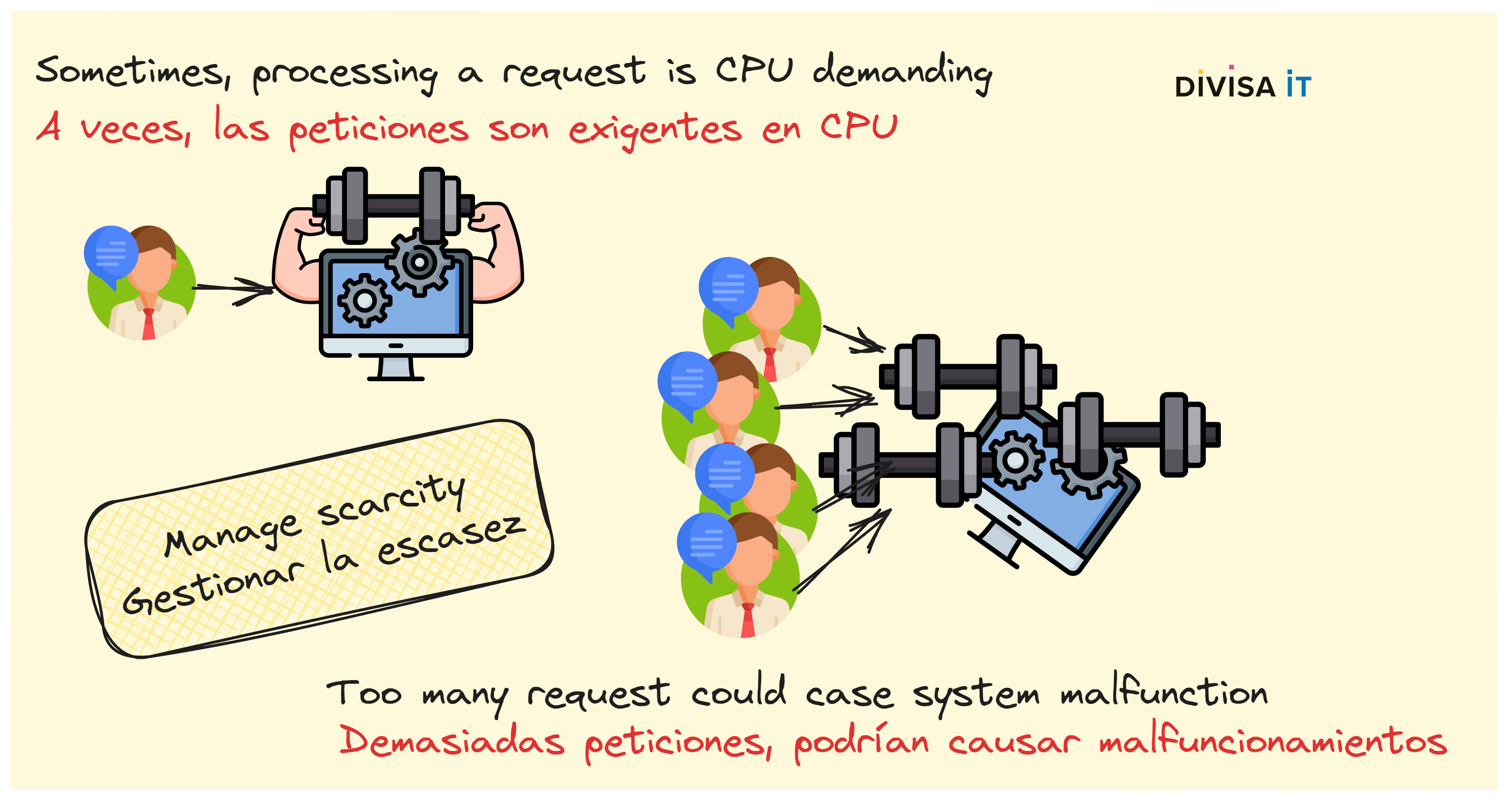
Actually, having CPU at 100% is not really a problem, but what happens if you are using Whisper to transform audio files to text. Logically, the more requests there are the more saturated the server is and the more slow the responses are going to be. Obviously you could think about adding more CPUS, GPUS or even servers. Yet, you should design your systems to be able to manage scarcity, CPU and machines are money, and you shouldn’t waste it.
Moreover, some tasks are also time-consuming. As a matter of fact, CPU issues and slowness tend to be correlated. If we continue using the Whisper example, the bigger the audio file is, the longer is going to be the time to transform it. Ignoring CPU related matters; do you know that there could be more problems? Actually the issue is related to how HTTP protocol is expected to work.
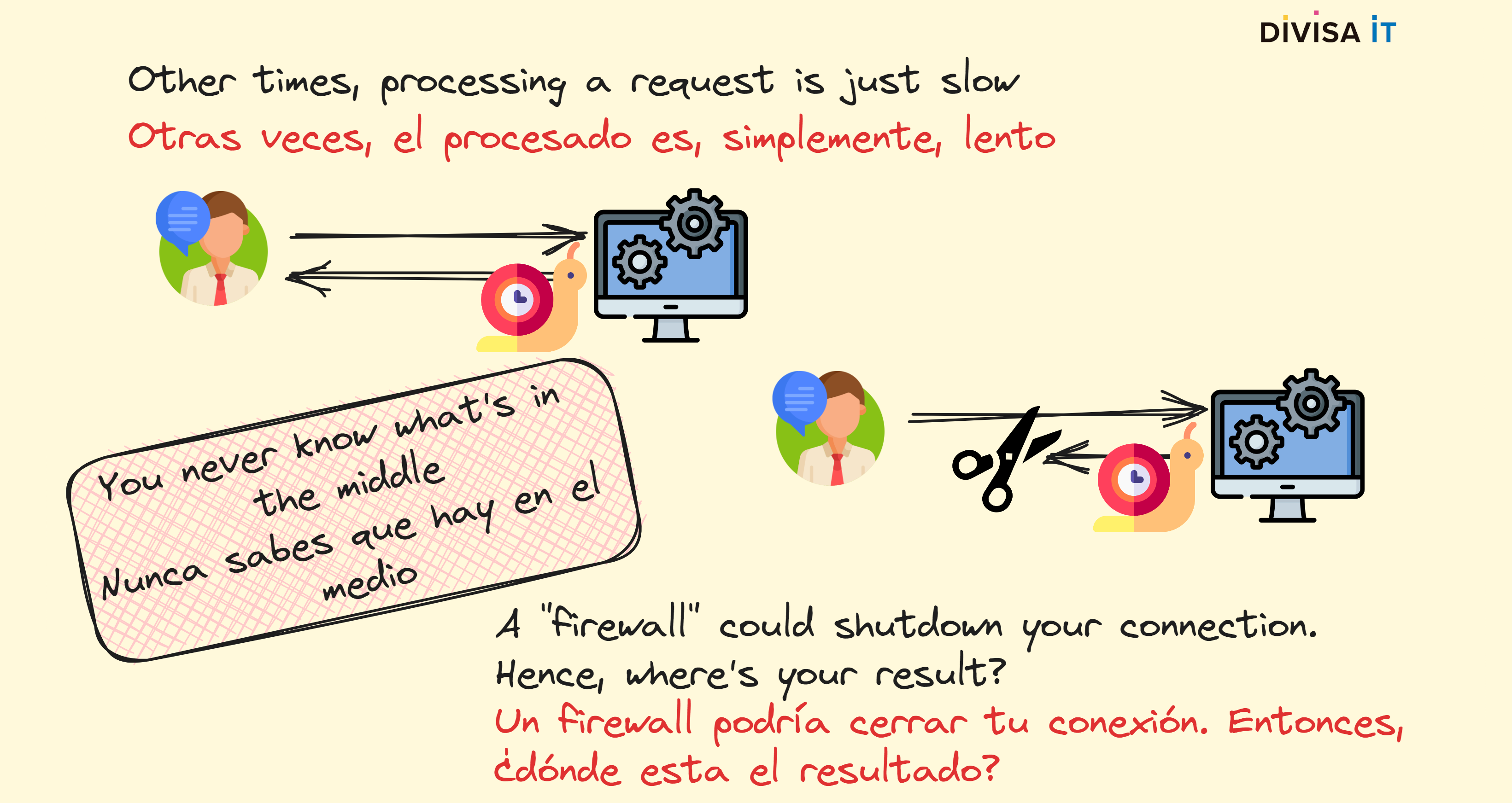
Effectively, HTTP protocol was designed supposing that response-time was going to be a short one. Actually, HTTP 0.9 closed the underlying TCP connection once the response was sent. While latter versions tried to address this problem, intermediate elements as firewalls tend to think that connections cannot live forever. Therefore, if a connection is opened for a long time the firewall could decide to drop it. Hence, your client is not going to know what have occurred, what could it do? Would it try to send a new request? Just imagine the increasing problem that your server would have to address.
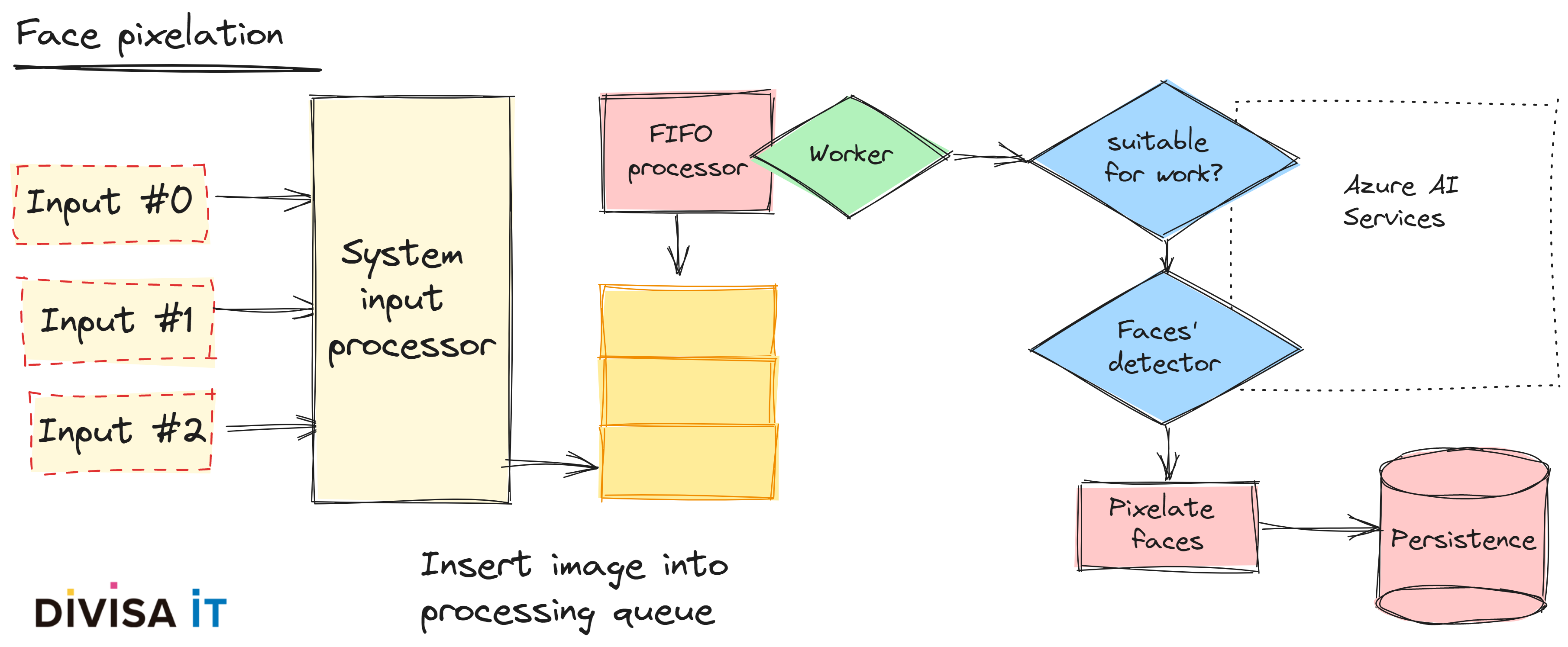
Thereby, I hope that I’ve been able to show you that there is a potential issue, so once we are aware about it, we should design our systems to avoid problems. What could be the solution? In fact it’s a combination of two, on the one hand a pretty simple m-1 producer-consumer problem and, on the other hand, our server should perform tasks in background while providing client with an immediate return. I’m talking about enqueuing and multi-threading but also about reporting client the result.

Actually, enqueuing and multi-threading issues are quite straightforward, so we need to focus on reporting client the task result. There are different ways to solve this problem, you could even try to use websockets but, in my opinion, the simpler the better. Besides, using websockets don’t isolate you for intermediate element misbehavior, dropping connections or even disallowing websocket traffic. Therefore, what are the possible solutions?

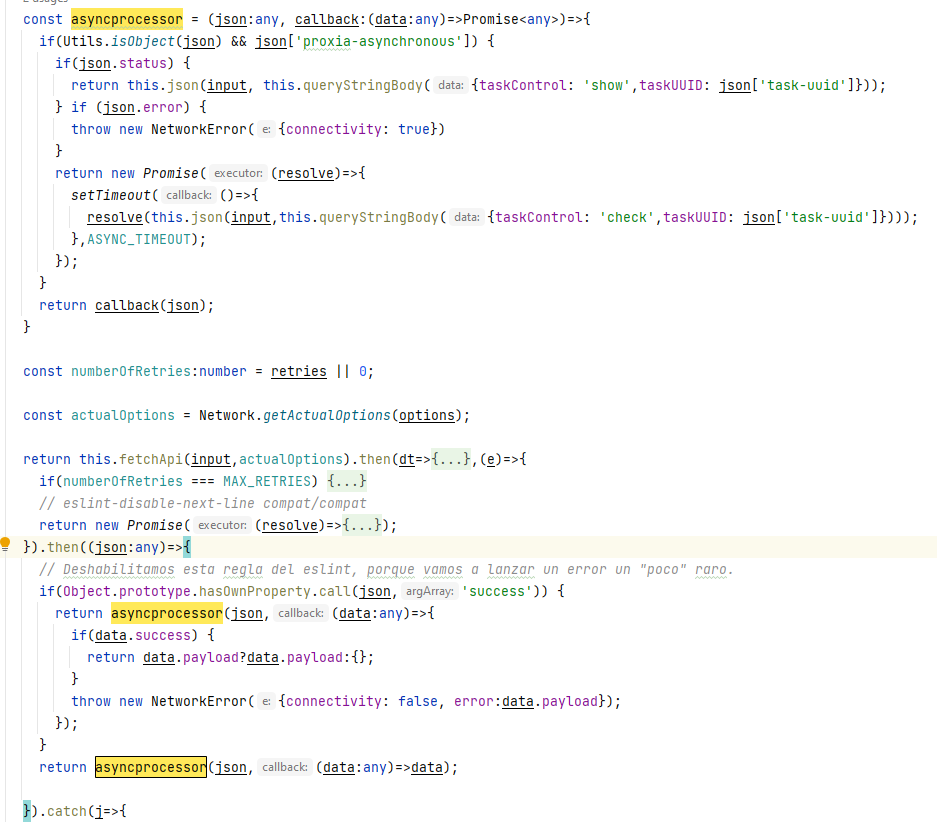
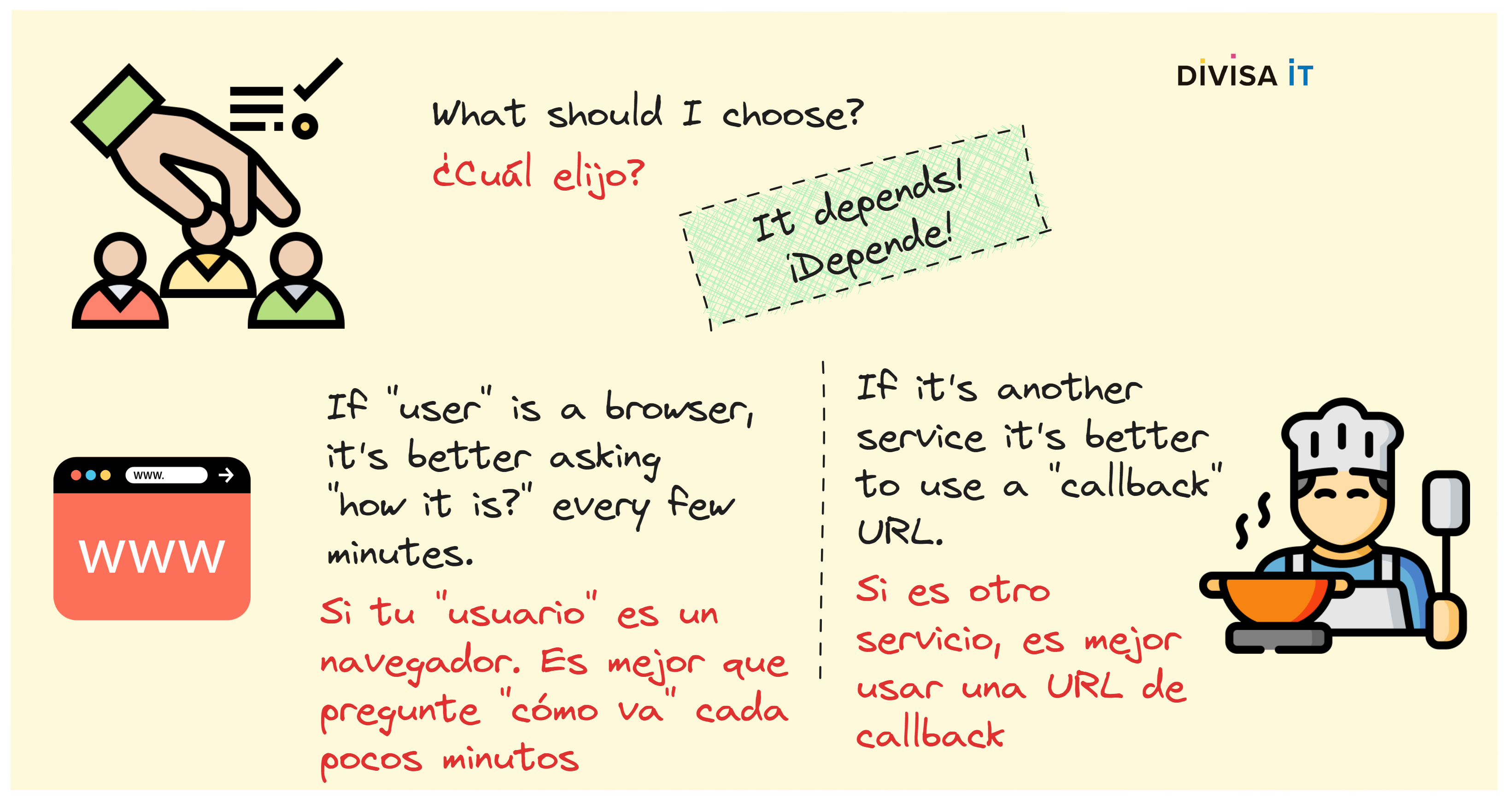
Both of them are pretty simple, the first one focus on client accountability while the last one on server one. Implementing the first scenario is about defining a protocol and questioning server every few seconds about request status. At Divisa iT we have used this approach in our frontend and backend stack, following image shows you our client fetch wrapper.
The later one is about using callbacks, while this approach is very typical when programming in both server and client-side, using promises; futures; whatsoever. However, it’s not so easily implementable when we are involving a communication protocol which doesn’t directly support this approach. Therefore using it for browser to server communication, doesn’t seem viable.
You could wonder if it wouldn’t be better to use always the first approach, both for client-server and server-server communication. In my opinion that’s not a good idea. Let’s see it, imagine that you are trying to implement it in a server to server communication. In the simpler approach, and not using Node on the server-side, you should have to create a new thread to check the result. Hence you could end up with a lot of threads. If you are not using green-threads you could face several performance issues. Obviously, there are more complex approaches, but they involve new queues, and new problems.
If you are further interested I have prepared a small Github repo  where you can find a Python example of a flask server that:
where you can find a Python example of a flask server that:
While uncomplicated it provides a good starting point for developing some kind of micro-services that could be used to perform AI related tasks, I mean to say, slow and CPU-consuming ones.
 David Rodríguez AlfayateTechnology, products and special software projects Manager.
David Rodríguez AlfayateTechnology, products and special software projects Manager.