Cargando...
La innovación, nuestra razón de ser
Seamos realistas, algunas tareas se comen la CPU, otras son lentas y otras se comen tanto la CPU como el tiempo de ejecución. Imaginad por un momento que alguna de esas tareas se invoca a través de un servicio REST, ¿sois realmente conscientes de los problemas que podrían ocurrir? Quizá os preguntéis que porque ibais a querer hacer eso. Permitidme que os cuente dos pequeños secretos. Por una parte, vuestro usuario siempre va a querer hacer todo desde un precioso interfaz, por otra parte, si vuestra aplicación hace algo más complicado que leer o escribir en una Base de datos, más tarde o más temprano os lo vais encontrar. ¿Queréis ejemplos? Sólo un par de ellos, uno puede ser rellenar una Base de datos y otro ejecutar una tarea que involucre algo de Inteligencia Artificial y que llevo algo de tiempo.
Así pues, una vez que estéis de acuerdo en que tenemos un problema potencial, deberíamos analizarlo. Antes de nada y aunque sea una obviedad os recuerdo que un servidor HTTP puede atender a varias peticiones al mismo tiempo. Veamos, si mis tareas se comen la CPU, ¿cuál es el problema?
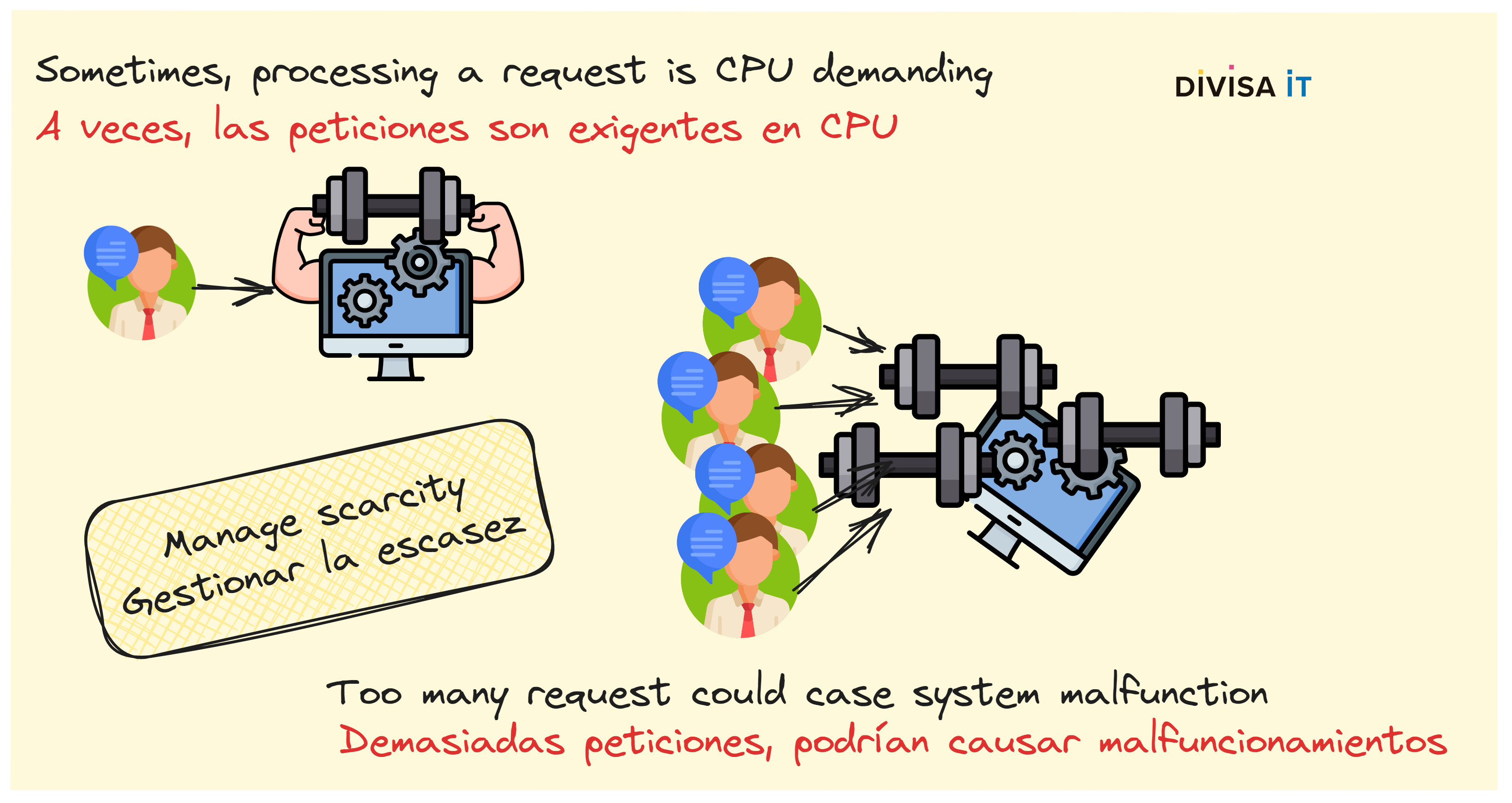
A decir verdad tener la CPU al 100% tampoco es un problema, pero imaginaos que, por ejemplo, usáis Whisper para transformar ficheros de audio a texto, una operación que a nivel de CPU es "ligeramente" pesada. Como os podéis imaginar, a más peticiones más saturación del servidor lo cual implica que tardará más en procesar las peticiones. Obviamente podéis decirme que eso no es un problema, se añaden nuevos servidores, más o mejores CPUs y GPUs. ¡Vale, de acuerdo! Pero deberíais diseñar vuestros sistemas para ser capaces de gestionar la escasez. Tanto las máquinas como las CPUs son dinero y, por tanto, no deberíamos desperdiciarlos.
Más allá de todo esto, algunas tareas también son lentas. La verdad, es que suele existir una correlación entre lentitud y uso de la CPU. Continuando con el ejemplo de Whisper, cuando mayor sea el fichero de audio más tiempo se va a tardar en procesarlo. Obviando los problemas de la CPU, ¿sabéis que puede haber más problemas? De hecho éstos se relacionan con cómo se espera que funcione el protocolo HTTP.
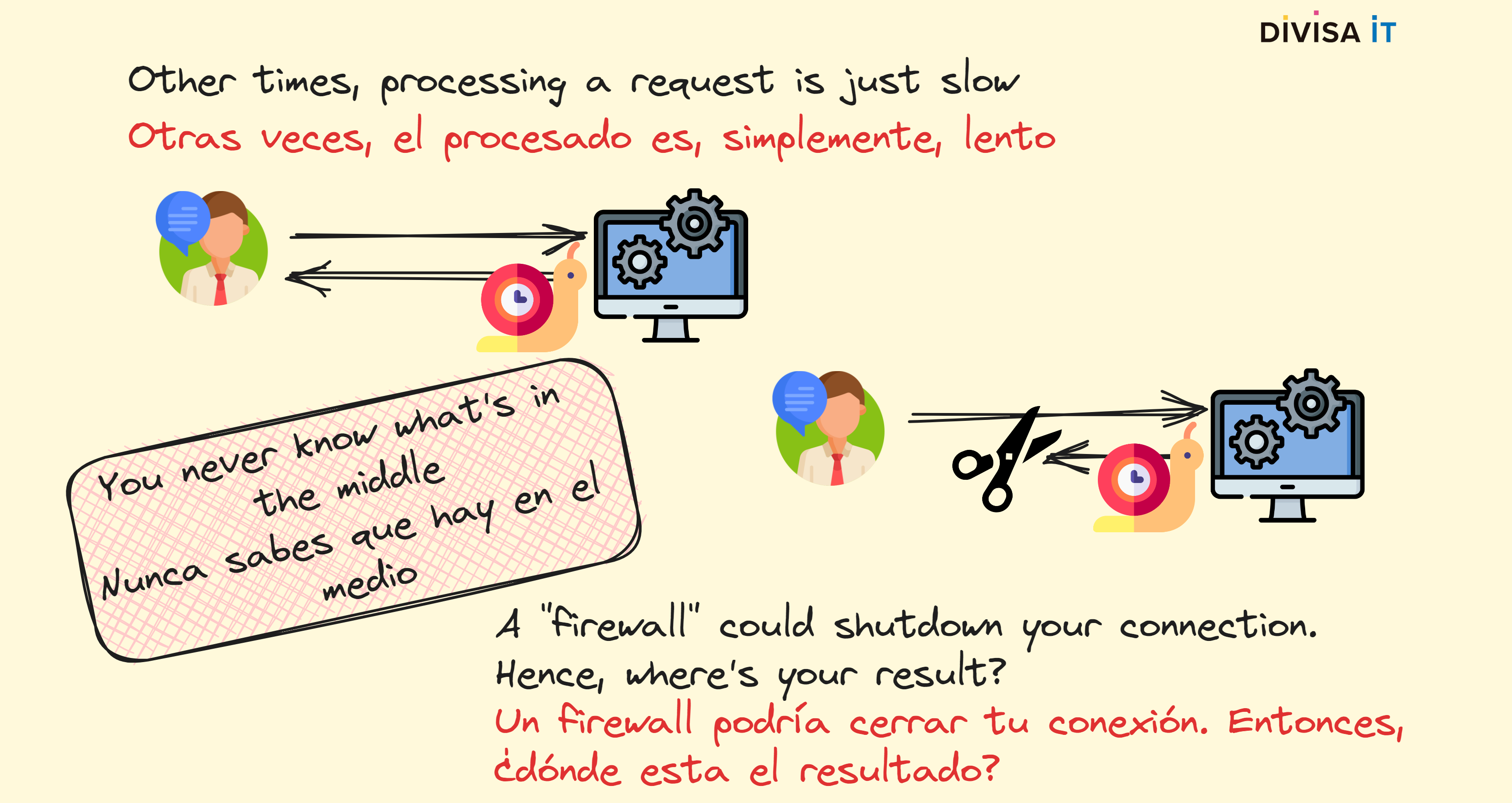
Efectivamente, el protocolo HTTP se diseño suponiendo que el tiempo de respuesta iba a ser "corto". De hecho en HTTP 0.9 descartaba la conexión TCP una vez que la respuesta había sido emitida. Si bien versiones posteriores tratan de soslayar este problema, no lo es menos que elementos intermedios como firewalls suelen pensar que las conexiones no están vivas por siempre. Por tanto, cualquier elemento intermedio podría decidir que si una conexión lleva abierta mucho tiempo es candidata a ser descartada. Esto es ligeramente problemático, ¡nuestro cliente no va a saber que ha pasado! ¿Qué va a hacer? ¿Realizar una nueva petición? Imaginaos como iba a quedar nuestro servidor si esto pasa de forma repetida.
Espero que hasta ahora haya podido demostraros que tenemos un problema potencial, así que una vez que somos conscientes lo que debemos hacer es diseñar nuestro sistema para evitar problemas. ¿Cuál podría ser la solución? De hecho es una combinación de dos, por una parte un problema m-1 productor-consumidor y, por otra, nuestro servidor debería realizar las tareas en background proporcionando al cliente una respuesta inmediata. De hecho de lo que estoy hablando es de encolado, multi-hilo pero también de enviar al cliente el resultado.

Como sabéis, los problemas de encolado y multi-hilo son de solución bastante directa, necesitamos, por tanto, enfocarnos en como informar al cliente del resultado de la tarea. Existen varias alternativas, incluso websockets aunque, en mi opinión, cuanto más simple mejor. Además, utilizar websockets no previene del problema de que un elemento intermedio se comporte de "aquella manera", cortando conexiones websockets o incluso deshabilitando. Entonces, ¿de qué estoy hablando?

Ambas dos son bastante simples, si bien la primera se enfoca en la responsabilidad del cliente y la segunda en la responsabilidad del servidor. Implementar el primer escenario es, simplemente, definir un protocolo y preguntar al servidor cada pocos segundos: ¿cómo va lo mío? En Divisa iT hemos utilizado esta aproximación en nuestra pila backend y frontend, en la siguiente imagen os enseño un wrapper que tenemos sobre las peticiones fetch para soportar este comportamiento.
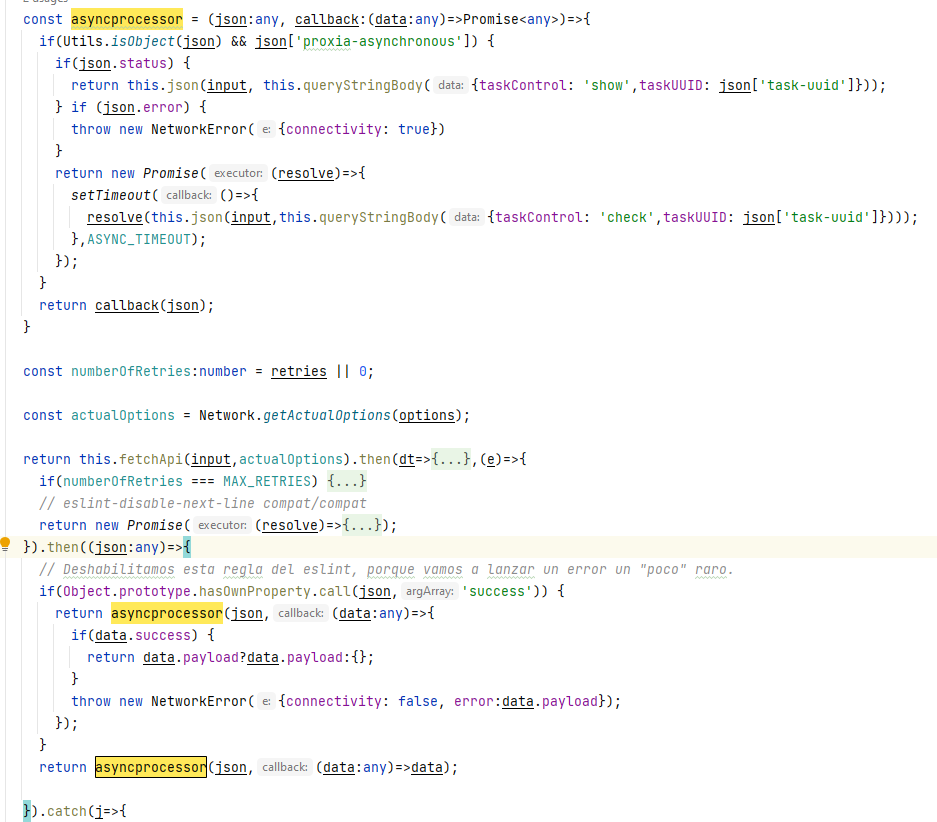
El último caso es simplemente utilizar funciones de callback, esta aproximación es muy típica cuando estáis programando, utilizando técnicas como promises, futures o cualquier otra. No obstante no es tan fácil de implementar cuando lo que tenemos es un protocolo de comunicación que no funciona exactamente así. Por tanto, utilizarlo para la comunicación entre el navegador y el servidor no parece viable.
Podríais preguntaros si no sería mejor utilizar siempre la primera aproximación, tanto para los escenarios navegador-servidor como servidor-servidor. En mi opinión no es una buena idea. Veamos, imaginad que lo intentáis implementar en una comunicación entre servidores, suponed que no usáis Node, eso os implica crear hilos para comprobar el resultado, lo cual podría suponer terminar con un montón de ellos. Si no se utilizan green threads podríais tener varios problemas de rendimiento. Aun así, existen aproximaciones eficaces pero más complejas, que creo que no compensan.
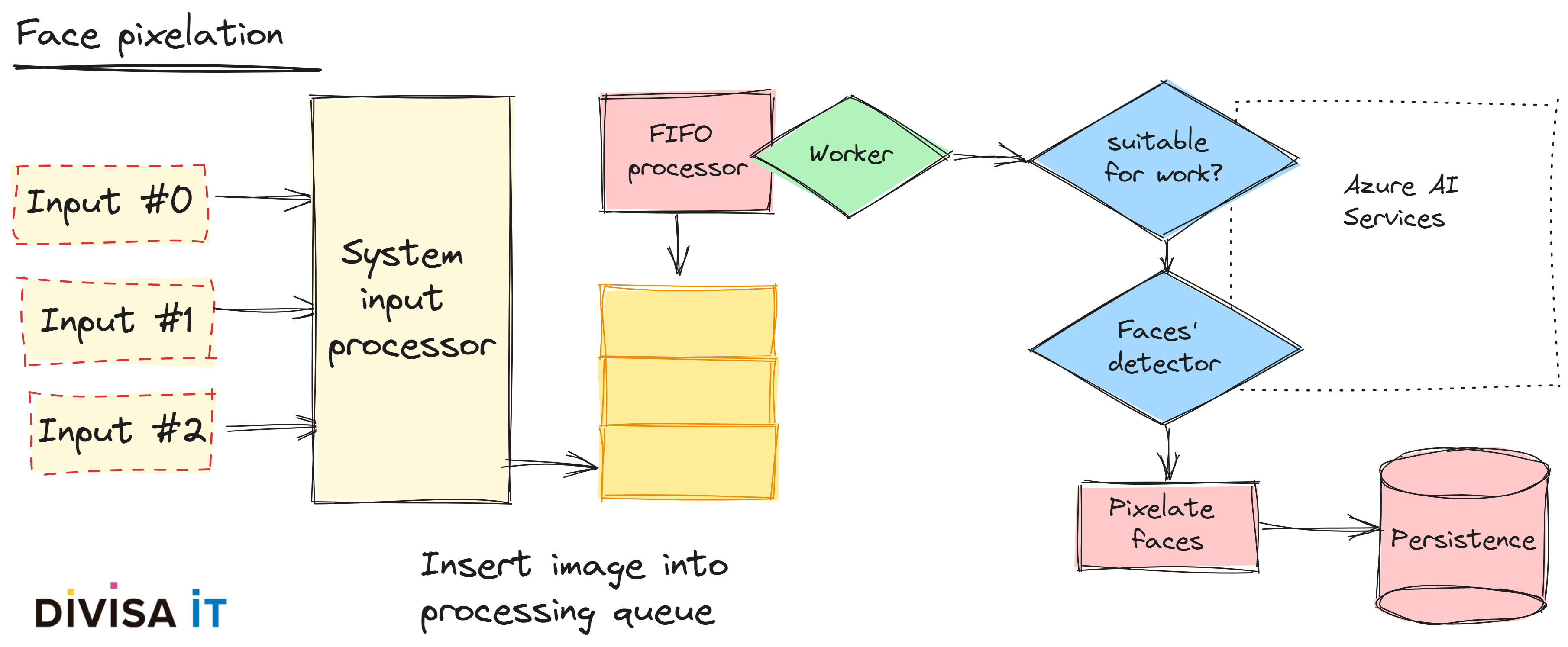
Si estáis más interesados os he dejado un pequeño Github repo dónde podeis encontrar un ejemplo en Python de un servidor flask que:
dónde podeis encontrar un ejemplo en Python de un servidor flask que:
Si bien simple, creo que puede proporcionaros un buen punto de arranque para desarrollar algún tipo de micro-servicio que podría requerir tareas de IA, es decir, tareas que pueden ser lentas y con altas demandas de CPU
 David Rodríguez AlfayateDirector de Tecnología, Productos y proyectos especiales
David Rodríguez AlfayateDirector de Tecnología, Productos y proyectos especiales