Loading...
Innovation, our reason for being
Unquestionably, one of the most typical problems that you have to face when you develop a software system is searching. As a matter of fact, I suppose that none of us consider searching as a complex task since you are typically using a storage system which is supposed to provide you with all the required capabilities, even though you could be requested to create some indexes in order to boost performance.

Nonetheless, problems begin to appear when you have text, sentences or even long paragraphs. A first approach could involve using pattern-based-search but, as you know, the issue becomes a bit harder when you notice that your text includes mixed cased words or you don’t have only English characters, mainly those with an accent mark. To make things worse, this pattern-based-search is not very efficient when you need to find a word in the middle of a paragraph.
However, you could argue that most storage systems support some kind of full-text capabilities. You are right, but I wonder if you have ever thought about what happens under the hood. If you are considering whether this is actually important or not, let me tell you something, comprehending the basis can provide new ideas, innovation is based on former knowledge and there are always situations in which standard capabilities are not enough for your use case. Besides, if you are interested on NLP, consider that although these systems go further, they use some of the same principles as full-text search.
At Divisa iT we have used this approach to build up Proxia’s out-of-the-box search engine. In our case I opted for this in-house approach to address two different problems, on the one hand to provide our clients with a database agnostic solution and, on the other hand, to avoid third-party systems usage unless they are already used by our clients.
When analyzing the problem, we have to consider that there is not an actual correlation between stored text and what the user looks for. We store long paragraphs, a plethora of sentences and different types of words, verbs, nouns and adjectives to name but a few, yet the user is searching for terms, sometimes misspelled and, probably, using a different derivative. Besides, your text could be in different formats namely plain text, PDF documents, Word documents or even Excel sheets.
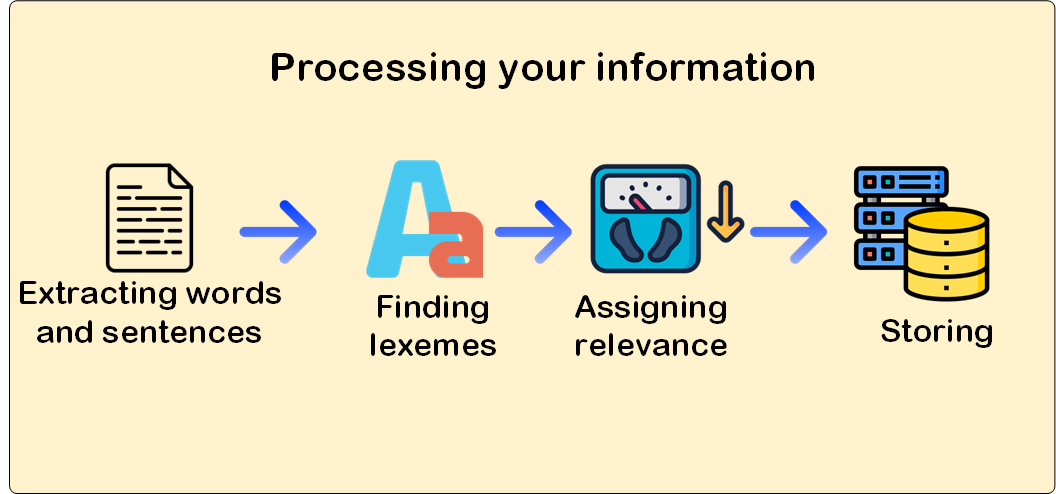
Therefore, as you could notice there are different issues to tackle in order to solve the problem completely,
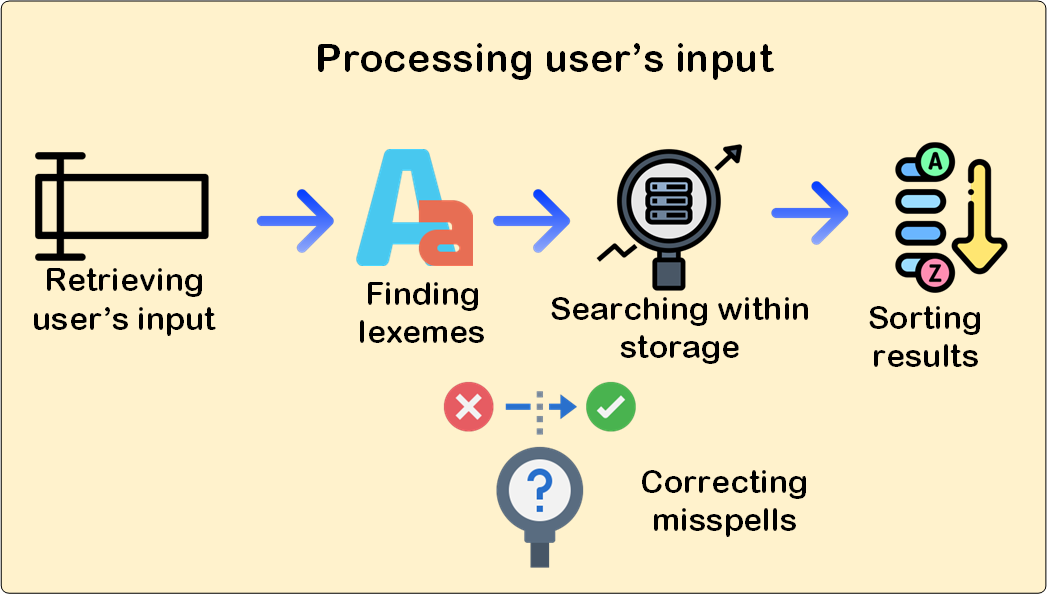
A lot of things to think about, isn’t it? There are many more items involved, for example, do all the words have the same importance when searching? do all users have access to all information? Describing all these things properly is a humongous task, there is really a plethora of information on the Internet that could help you to grasp a better understanding, so if you are really interested go for it, this book  has very good points and it helped me a lot. Here, I’ll give you just a glimpse of how we are addressing this problem at Divisa iT.
has very good points and it helped me a lot. Here, I’ll give you just a glimpse of how we are addressing this problem at Divisa iT.
My best advice, do not try to reinvent the wheel, there are very good open-source projects that solve this problem properly.
could help you to achieve your goals but, on the other hand, you will have to develop some heuristics in order to detect footer and headers sections, lines, sentences, and all those important things. is the tool for you. Quite handy, and ready to use.. If you need to go deep inside, you should perhaps consider acronyms, abbreviations and all those language related matters.First of all, extracting word lexemes is tough and complex. Do not try to do it on your own. Good algorithms which could help you are the following ones:
, there are different solutions for different programming languages and human ones – Spanish, English, etc. -. This algorithm is not really extracting the proper lexeme but an approximation considering some word formation rules. to extract lexemes. This algorithm uses a word database so its results are more accurate than Porters’ ones. On the other hand, it’s slower and trickier to use, and when using JVM you will have to use JNI to access its functionality.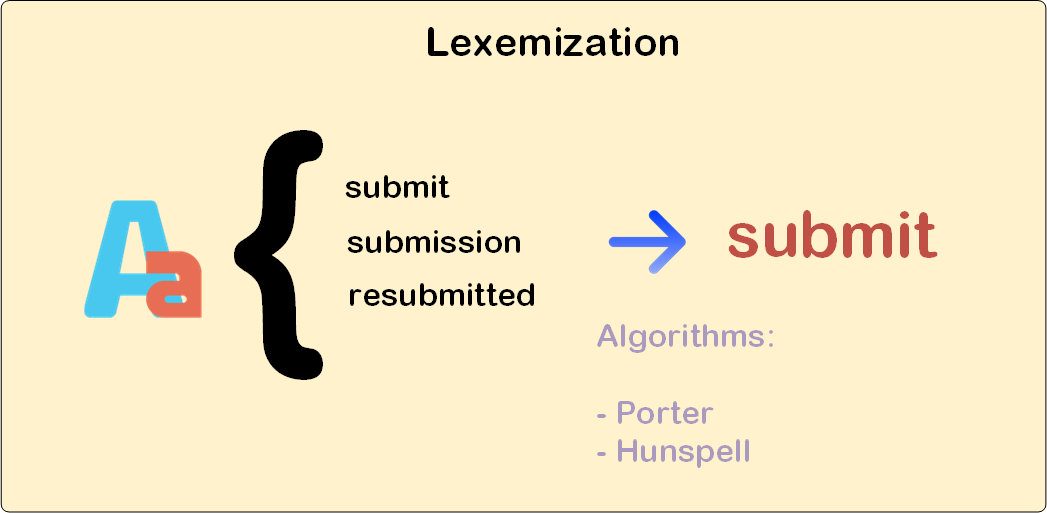
Be your election as it may, once tokenization step has finished it’s the moment of storage to be done. Former to this, token weight must be computed to control its importance or relevance within the document. You could think that this is an easy task, since the more times a token appears the more relevant it is. Of course, you are right, but besides frequency you should consider other aspects as, for example,
weight algorithm.Finally, if your solution is a database centric one, which its own RBAC subsystem, I would recommend using an Index Organized Table approach since its performance is much better than a traditional table, although inserts and updates are penalized. As a matter of fact, there are many other issues to consider, for example:
, but you will also have to store bi-grams, for instance the word "submit" will be divided into "su" "ub" "bm" "mi" and "it" bigrams. Using these bigrams and Jaccard index our system will be able to find candidate suggestions.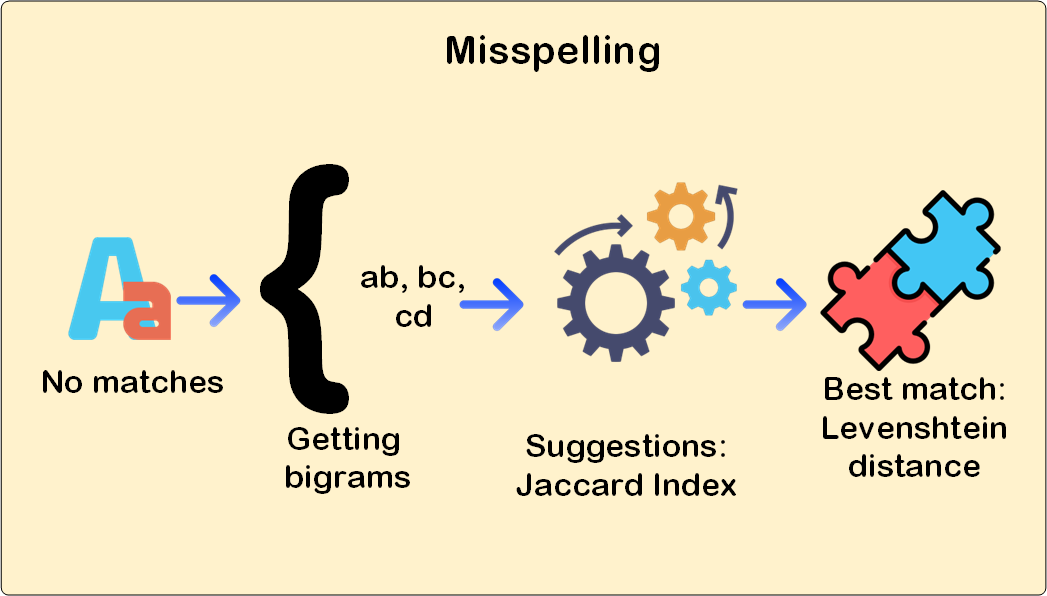
Final step is performing queries, as you can suppose the storage structure explained before makes easier to know which documents contain a concrete token. Nevertheless, queries don’t usually involve searching by only one token, in fact we have to consider different criteria and different conditions. Actually, executing the query is not tough at all, we only have to take into account how bitwise operation could help us.

This means that,
Last but not least, I should talk about how to sort search results. Weight, as computed before, is a good starting point, but only if all documents are equally important. Different algorithms could be applied and all of them depends on your use case and user and end-user expectations, some examples that we are using include:
Performing text-based queries is not actually complex, but there are different issues to be considered. In my opinion, just learning about lexemization, different algorithms and how it could be used to improve your search systems, even when working with in-memory approaches, it’s worth the time invested.
On the other hand, text-based search is only one of the different types of queries that can be performed. When you try to find information about namely states, towns, user names, to name there are perhaps better solutions, depending upon your use case, as Trie algorithms.
 David Rodríguez AlfayateTechnology, products and special software projects Manager.
David Rodríguez AlfayateTechnology, products and special software projects Manager.