Cargando...
La innovación, nuestra razón de ser
Indiscutiblemente, uno de los problemas habituales a los que nos tenemos que enfrentar cuando desarrollamos aplicaciones software es el de resolver las búsquedas. En realidad, me imagino que ninguno de nosotros considera que el buscar sea una tarea excesivamente compleja. A fin de cuentas, solemos utilizar las capacidades nativas del sistema de almacenamiento, el cual se supone que nos proporciona todo lo que necesitamos, aunque a veces sea necesario crear algunos índices a la hora de mejorar el rendimiento global.

No obstante, el problema comienza a aparecer cuando tenemos texto, y por ello me refiero a frases o párrafos Una primera aproximación podría ser la realización de búsqueda en base a patrones, pero estoy seguro que sabéis que esta búsqueda se complica un poquito más cuando tenemos que considerar mayúsculas, minúsculas o caracteres acentuados. Para complicar todo un poquito más, la búsqueda basada en patrones no es muy eficiente cuando tenemos que buscar una palabra en medio de un texto muy largo.
Llegados a este punto me podrías decir que, bueno, a fin de cuentas todos los sistemas de almacenamiento soportan algún tipo de búsqueda sobre todo el texto. De acuerdo, es así, pero, ¿os habéis preguntado alguna vez como funciona todo esto? Quizá penséis que esto, la verdad sea dicha, no tiene demasiada importancia. Dejadme deciros algo, la innovación se basa en el conocimiento anterior, entender los conceptos básicos nos ayuda a desarrollar nuevas ideas y siempre hay casos en que las soluciones por defecto no son suficientes. Por otra parte, si sentís curiosidad por cómo funcionan los sistemas NLP debéis saber que aunque estos sistemas son mucho más complejos si comparten ciertos principios básicos con las soluciones de búsqueda de esta naturaleza.
En Divisa iT hemos utilizado estas aproximaciones para construir el sistema de búsqueda nativo de Proxia. ¿Por qué algo construido en casa? Básicamente dos razones, por una parte Proxia es agnóstico respecto a la Base de datos e introducir consultas muy dependientes de implementaciones no SQL estándar es problemático y, por otra parte, porque no soy partidario de forzar a los clientes a montar entornos artificiosamente complejos salvo que ellos tengan esa necesidad o planteamiento previo.
A la hora de plantearnos el análisis del problema, lo primero que debemos tener en cuenta es que, a decir verdad, no existe una correlación exacta entre lo que se almacena y lo que el usuario busca. Veamos porqué, nosotros almacenamos párrafos, montones de frases y palabras de distintos tipos como, por ejemplo, sustantivos, adjetivos, adverbios. El usuario final, por su parte, introduce términos muchas veces mal escritos y, seguramente, utilizando distintas palabras derivadas aunque compartan la misma raíz que lo que tenemos guardado. Para complicar un poco más las cosas, el texto podría provenir de distintos orígenes, como texto plano, documentos en formato PDF, Word o incluso Excel.
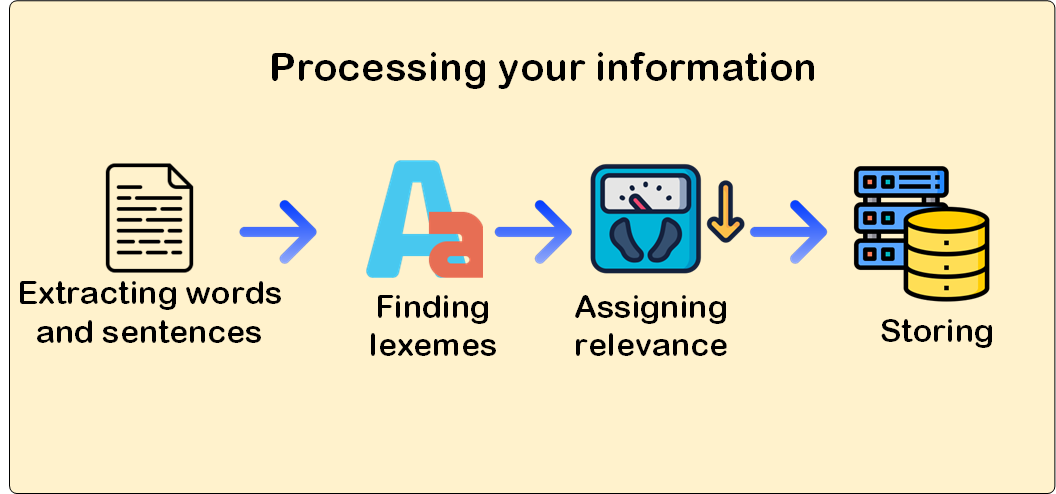
Así pues, tal y como podéis percibir hay varios problemas diferentes que debemos abordar a la hora de resolver el problema en su totalidad.
Un montón de cosas en las que pensar, ¿no?. Pues eso no es nada, hay muchos más temas involucrados, por ejemplo, ¿tienen todas las palabras la misma importancia cuando se busca?, ¿tienen los usuarios acceso a toda la información o solo a parte de ella? Daros una explicación completa y detallada de todos estos aspectos es inabordable, así que si estáis realmente interesados os recomiendo la lectura de este libro . Aquí me voy a limitar a daros unas pinceladas de como hemos resuelto estos problemas dentro de nuestros productos en nuestra compañía.
. Aquí me voy a limitar a daros unas pinceladas de como hemos resuelto estos problemas dentro de nuestros productos en nuestra compañía.
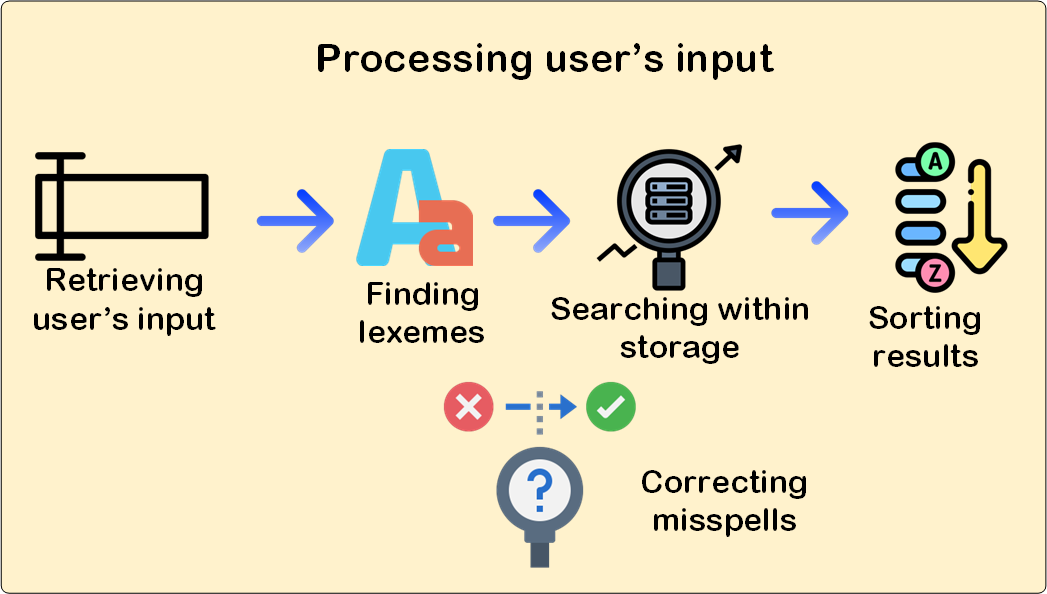
Mi consejo, no intentéis reinventar la rueda, hay varios proyectos open-source que resuelven este problema de forma muy satisfactoria, así que podéis mirarlos, plantearos que elementos son útiles y emplearlos en vuestras soluciones.
os permitirían resolver parte de vuestros problemas, aunque os tendréis que enfrentar a otros, desarrollando ciertos heurísticos para identificar elementos que no son "semánticamente relevantes", como pueden ser los pies de página, cabeceras. Ya sin mencionar la detección de frases (crítica para las búsquedas literales) son las más adecuadas. Bastante potentes y realmente sencillas de emplear.. Además, probablemente, os tocará hacer algo más como identificar abreviaturas, acrónimos, frases y todas esas cosas maravillas del lenguaje.Antes de nada, buscar los lexemas no es nada fácil, más bien todo lo contrario. Así que no intentéis nada por vuestra cuenta, existen estupendos algoritmos que os podrían ayudar a resolver este problema.
, hay soluciones para diferntes lenguajes de programación y lenguajes humanos – español, inglés, etc. – En realidad, este algoritmo no extrae el lexema real sino una aproximación basada en las reglas de formación de palabras. para extractar los lexemas. Este algoritmo se apoya en una base de datos de palabras, así que ofrece resultados mucho más precisos que los de Porter. No obstante, es más lento y un poquito más complejo de usar que el de Porter, sobre todo si utilizáis un lenguaje basado en la JVM y os toca utilizar JNI para acceder a su funcionalidad.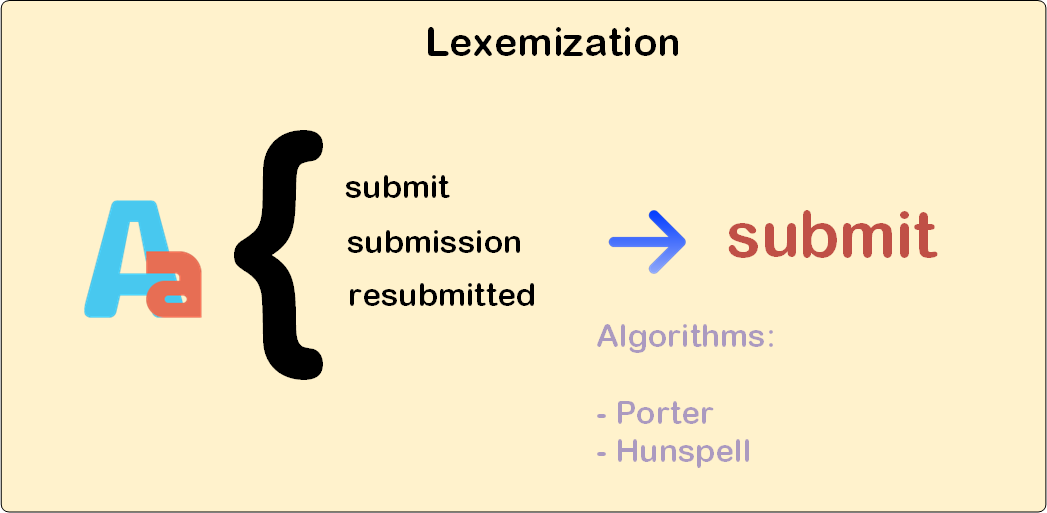
Hagáis lo que hagáis, una vez que el paso de la tokenización ha terminado es el momento de almacenar los datos. Pero antes de ello, deberíamos calcular el peso de cada token de tal forma que podamos saber como es de importante o relevante en el ámbito del documento. Aunque puede parecer algo trivial, a fin de cuentas es contar cuantas veces aparece, no es sólo una cuestión de frecuencias, sino que existen otra serie de aspectos a considerar como, por ejemplo,
Una vez que tenemos esto claro, ya podemos proceder a almacenar los datos. Pensemos en el caso más simple una base de datos en el que además tenemos un sistema RBAC, en esta situación os recomendaría que utilizarais tablas organizadas como índices, puesto que el rendimiento que nos ofrecen para esta problemática es muchísimo mayor que el de las tablas tradicionales, aunque se penalizan los procesos de inserción y actualización. En cualquier caso almacenar, no es sólo guardar los tokens sino que, además,
, sino que, además, tendremos que dividir nuestras palabras en bigramas, así la palabra "avión" se guardaría como "av", "vi", "io" y "on", para luego utilizar el coeficiente de Jaccard a la hora de buscar sugerencias.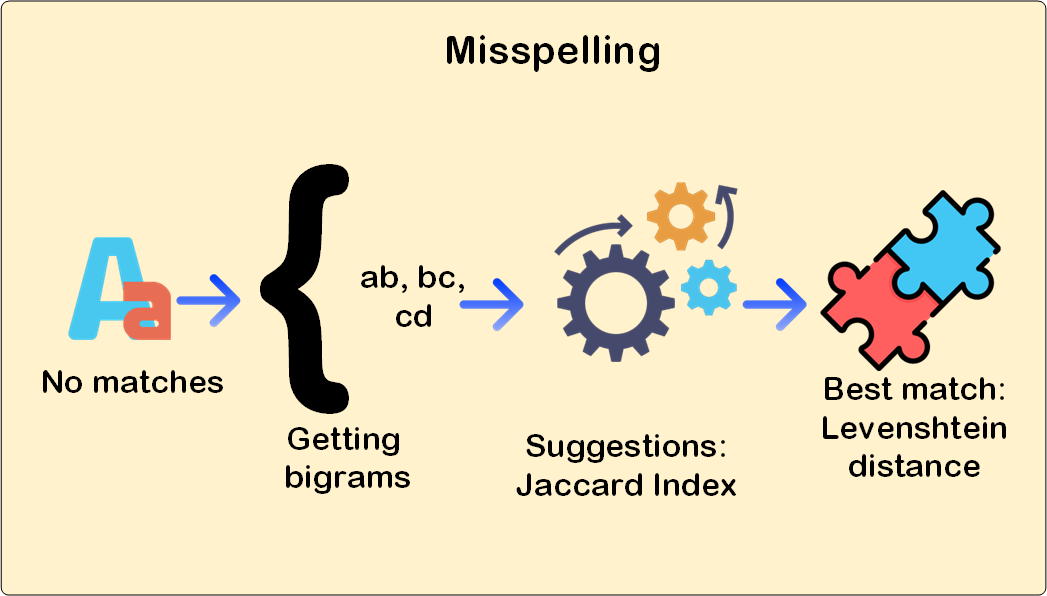
Por fin, ahora ya que tenemos todo colocado en su sitio podemos realizar las búsquedas, aparentemente fácil teniendo en cuenta la estructura de almacenamiento. Pero, claro, como os comentaba antes las búsquedas no sólo involucran a un único token, sino que debemos considerar distintos criterios y condiciones. Bueno, tampoco es muy complicado, un poco de lógica binaria es suficiente para resolver el problema.

Así pues,
Ya, para terminar, me gustaría daros una última pincelada de como ordenar los resultados de la búsqueda. El peso, tal y como lo computamos antes, es un buen punto de entrada pero sólo si los documentos tienen la misma importancia. En caso contrario podríamos aplicar distintos heurísticos en función del caso de uso que tengamos entre manos y las expectativas del usuario final, algunos ejemplos que usamos incluyen:
Realizar búsquedas sobre el texto no es, en realidad, complejo pero existen varios aspectos a tener en cuenta. En mi opinión, adquirir conocimientos sobre como aplicar lexemización, los diferentes algoritmos involucrados y como pueden utilizarse para mejorar los sistemas de búsqueda, aun usando aproximaciones en memoria, compensan el tiempo invertido.
Por otra parte, la búsqueda "textual" es sólo uno de los distintos tipos de búsquedas que pueden plantearse sobre la información de naturaleza textual. Sólo por comentarlo, si lo que intentáis es buscar información sobre provincias, municipios o nombres de usuario quizá un algoritmo tipo Trie sea mucho más adecuado.
 David Rodríguez AlfayateDirector de Tecnología, Productos y proyectos especiales
David Rodríguez AlfayateDirector de Tecnología, Productos y proyectos especiales