Cargando...
La innovación, nuestra razón de ser
De forma recurrente cuando hago entrevistas, he percibido que quizá sean las anotaciones una de las características más usadas pero menos conocidas del lenguaje Java.
Por una parte, creo que, más o menos, todo el mundo que trabaje con Java hoy en día esta acostumbrado a usarlas en librerías o frameworks como Spring o Hibernate. Pero, esa utilización no se ve acompañada por la capacidad de explicar lo que son, si tiene sentido crear anotaciones personalizadas y que hay detrás de Hibernate o Spring.

Las anotaciones se relacionan con un concepto que es la meta-programación. De forma muy poco ortodoxa, podríamos definir a una anotación como algo que permite etiquetar declaraciones (campos, métodos, parámetros y clases) con cierta información. Esta información será utilizada por un procesador externo que leerá esos datos y decidirá que hacer con ellos.
Siendo sincero, no es una definición muy brillante, y seguro que os preguntáis de que tipo de control os estoy hablando. Creo que no hay nada mejor que una serie de ejemplos, así que aquí van:
 y sus anotaciones pesonalizadas., estáis de hecho "conectando" clases al motor de controladores de Spring. o modificando el bytecode con la ayuda de librerías como ASM.
y sus anotaciones pesonalizadas., estáis de hecho "conectando" clases al motor de controladores de Spring. o modificando el bytecode con la ayuda de librerías como ASM.De todas estas la más compleja es la última, no os recomiendo hacerlo salvo que no os quede más remedio que manipular el bytecode – como fue en nuestro caso –, es una técnica no especialmente sencilla y sujeta a multitud de puntos de fallo. De todas formas los demás tipos de anotaciones (incluso las basadas en Proxy) son bastante sencillas, proporcionan valor, y además os permiten adquirir un mayor conocimiento del lenguaje Java (y otros relacionados).
A continuación os muestro un pequeño ejemplo del uso de anotaciones y porque nos permiten resolver problemas.
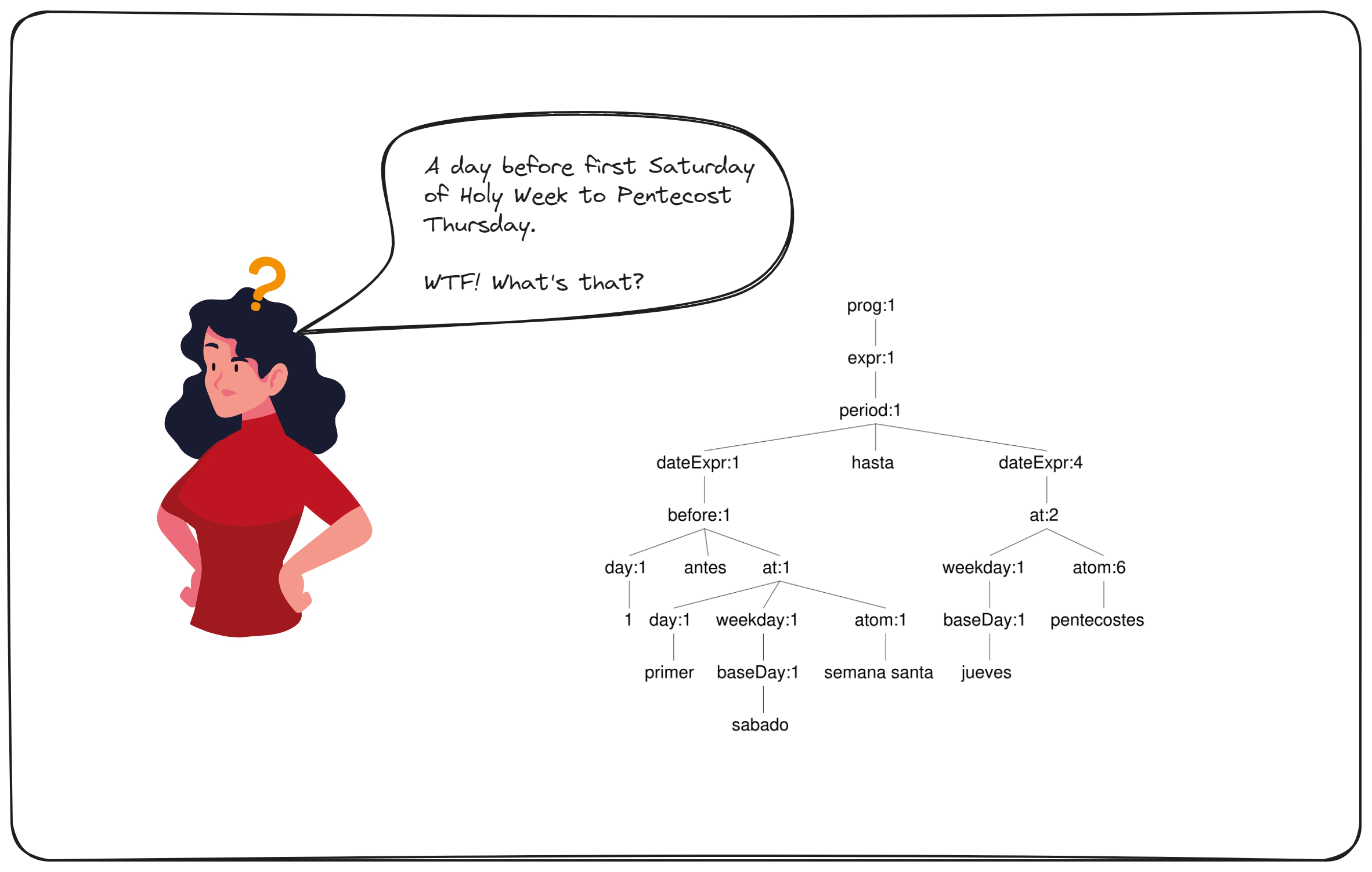
Imaginaos que queremos rellenar una Base de datos partiendo de una serie de ficheros. Indudablemente tendremos que resolver muchas cuestiones, aunque quizá destacaría dos:
Vamos a considerar que la respuesta es afirmativa a ambas cuestiones. Tendríamos que dar respuesta a problemas relacionados con como almacenar objetos de tipos distintos y como detectar si un registro se ha modificado. El primero de los problemas pasaría por usar, por ejemplo, un almacén basado en BLOBS o una Base de datos NoSQL.
El otro problema es distinto, detectar si un objeto ha mutado puede resolverse de varias formas, para mi una de las más sencillas es generar un HASH (MD5 o SHA1) del objeto y comparar el hash del objeto origen con el del objeto destino.
Como sabéis la generación del hash no es complicada, pero debéis tener en cuenta que un objeto no es sólo propiedades sino que se almacena otra información como el estado o campos calculados. Lógicamente, el estado y quizá incluso los campos calculados, no forman parte del hash, pero quizá si queramos almacenarlos en la Base de datos.
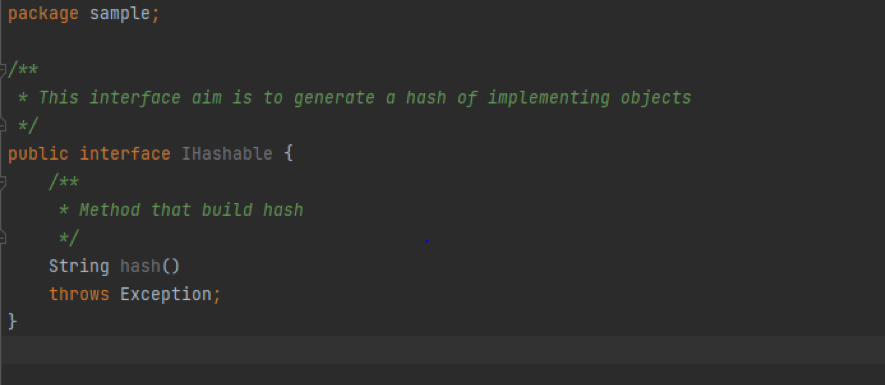
El prototipo que usaré en todas las soluciones que os voy a contar es en todos los casos el mismo, un interfaz que será responsable de implementar el hash.
En este caso utilizaremos Gson y su soporte de anotaciones como @Expose. Esta aproximación es simple y funciona francamente bien:
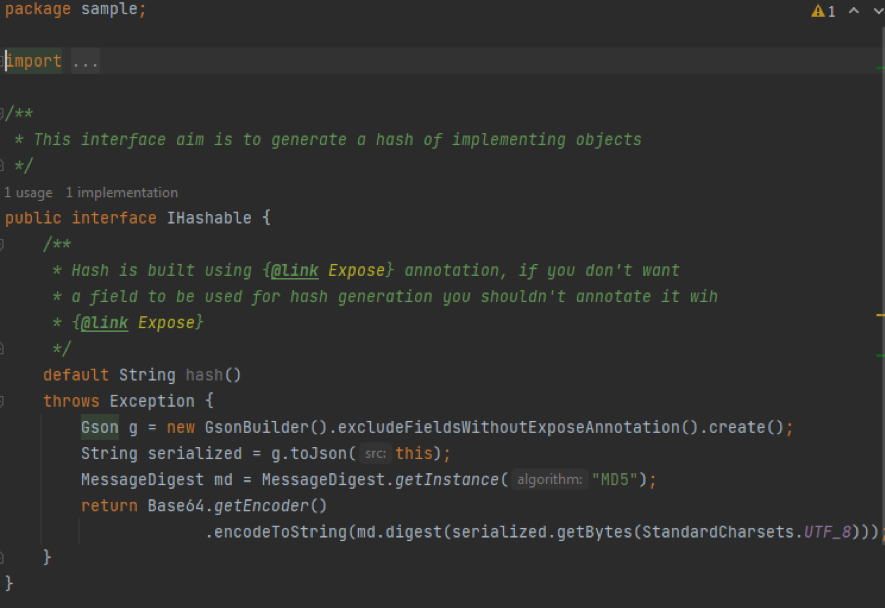
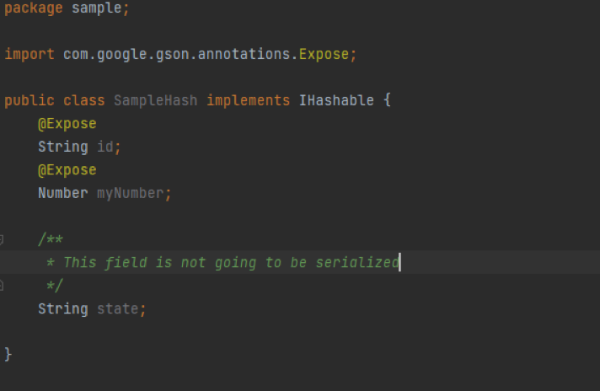
Sin embargo, adolece de dos problemas fundamentals:
En este caso utilizaremos una anotación personalizada @HashHidden que incluiremos dentro de Gson. Esta aproximación es casi tan simple como la anterior, y además nos permite resolver los problemas que antes habíamos presentado.
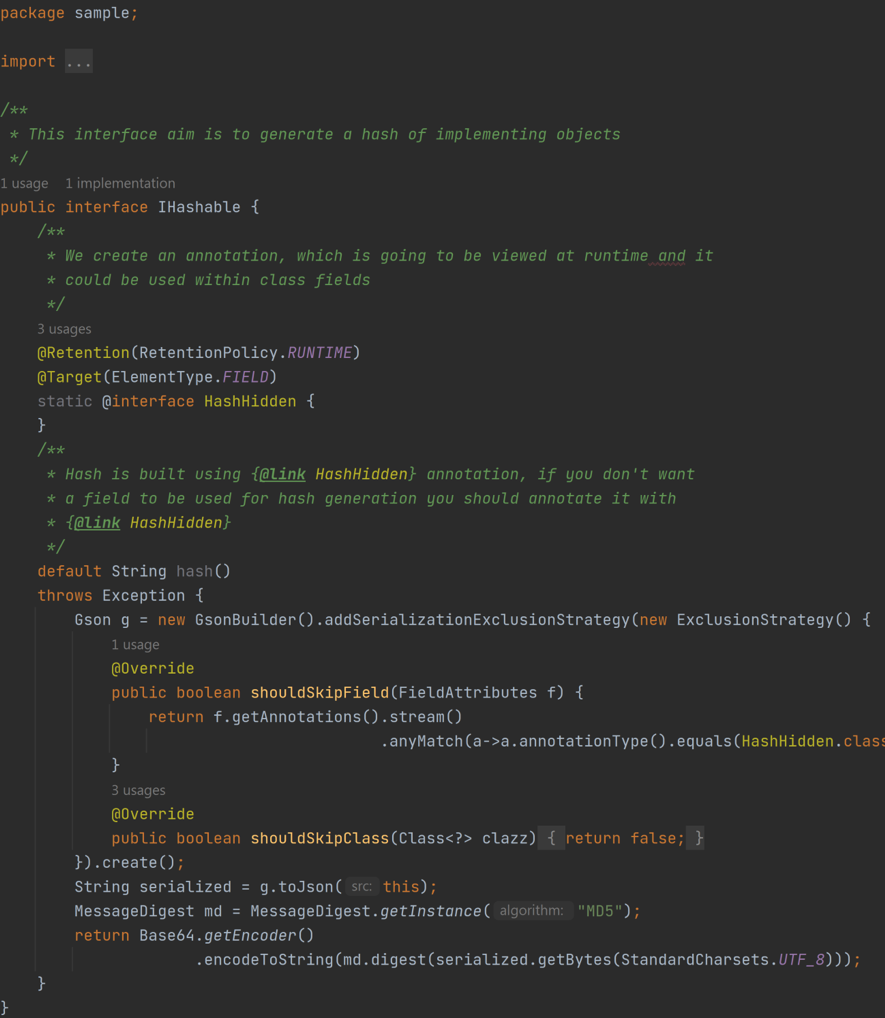
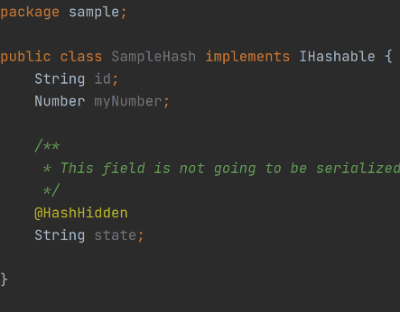
Como veis, no solo se introduce una nueva keyword, @interface, sino que también tenemos que utilizar dos anotaciones estándar de Java que nos definen como nuestro @HashHidden va a funcionar: @Retention y @Target. Os lo cuento en más detalle.
Si lo que os interesa es ver las tripas para ver como la magia de las anotaciones funciona, creo que esta solución es para vosotros. Si, por otra parte, vuestro problema es distinto al que os he contado antes, que seguro que si, tened en cuenta que las soluciones basadas en generar un JSON no os van a valer y necesitareis saber un poco más.
En este caso partimos de nuestro estupendo @HashHidden y utilizaremos reflexión para recuperar los campos, sus valores y sus anotaciones.
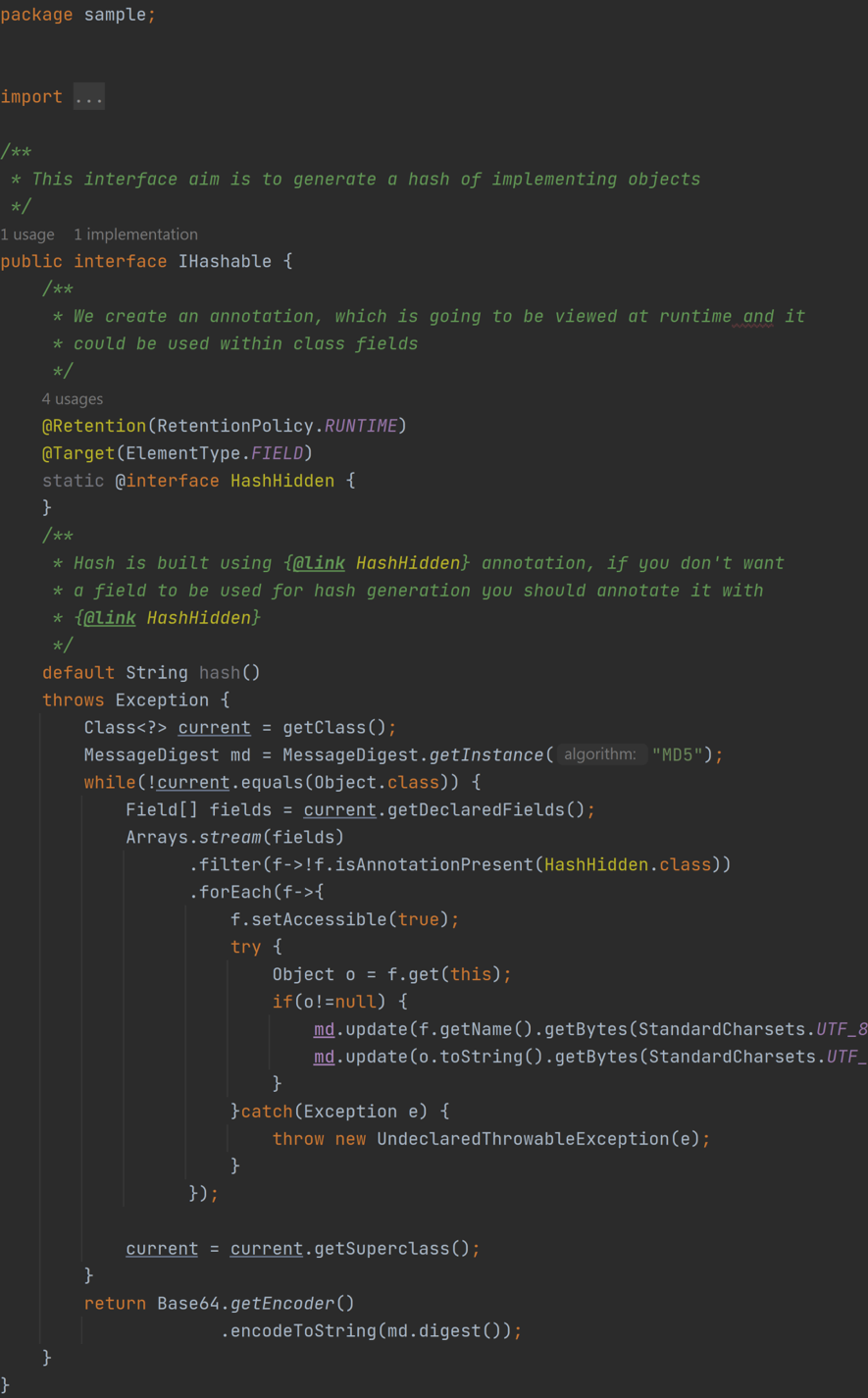
Como podéis ver se trata de un ejemplo muy simplificado, en el cual los valores se transforman a cadenas. Pero creo que os puede dar una idea de cómo pueden utilizarse las anotaciones de una forma algo más compleja.
Una anotación no es solo un cascarón vacío, sino que se pueden definir campos que tienen propiedades tales como:
De alguna forma podéis imaginar el uso de las anotaciones como si crearais un JSON en un lenguaje como JavaScript
En Divisa iT hemos utilizado anotaciones con profusión dentro de nuestro framework, como por ejemplo:
Los iconos utilizados son cortesía de Flaticon
 David Rodríguez AlfayateDirector de Tecnología, Productos y proyectos especiales
David Rodríguez AlfayateDirector de Tecnología, Productos y proyectos especiales