Cargando...
La innovación, nuestra razón de ser
Las herramientas son sólo eso, herramientas. Por tanto e ignorando todo el ruido alrededor de las mismas, lo que debemos hacer con el objeto de utilizarlas de forma adecuada es localizar una situación que no sea facilmente resoluble sin ella. Sin lugar a dudas, el año 2023 ha sido el año de la IA, sobre todo de la generativa. Estoy convencido de que o bien habéis oído hablar de ella o bien lo habéis utilizado, bien sean sus capacidades de generación de código o imagen, todo ello sin dejar de mencionar sus características de lenguaje natural. Ahora bien, cuando reflexionamos sobre los problemas de los clientes, aquellos que requieren soluciones de ingeniería, las cosas cambian un poco.
A decir verdad, los problemas reales de los clientes no suelen ir de generar una imagen o hacer un chat autónomo, sino de embeber estas funcionalidades en un sistema más complejo. De esta forma, deberíamos ver la IA como un típico subsistema software, un engranaje en un mecanismo más complejo.
Teniendo esto en cuenta, me gustaría enfocarme en diferentes escenarios en los que en Divisa iT hemos utilizado las soluciones de IA en nuestros productos y proyectos. Todos ellos orientados a resolver diferentes problemas, pero, aún así, compartiendo la aproximación o la visión como subsistema anteriormente mencionada.
Uno de los sistemas software más típicos en los que puedo pensar es aquel que involucra la introducción de datos por parte del usuario. Imaginemos un entorno muy sencillo, el de la introducción de texto, no sólo deberíamos eliminar texto con palabras malsonantes, sino aquel que podríamos clasificar como insultante o aquel que tiene una opinión quizá excesivamente sesgada. Realizar esto de forma manual es pesado y consumirá mucho tiempo.
Pero, más allá del texto, nuestro usuario final podría también subir imagenes, que sino filtramos podría suponer la introducción de material con copyright, pornográfico e incluso rostros de personas anónimas. Emplear una simple exención de responsabilidad no va a ser suficiente, cuando manejamos material de este tipo, y nuestro cliente podría enfrentarse a problemas serios si no aplicamos algun mecanismo de mitigación.
Obviamente, podriamos evitar que esta información se publicara de forma pública. Pero, estaréis conmigo, en que existen situaciones en las que esta publicación seria deseable y, no sólo hablo de aplicaciones que podrían caer dentro de lo que llamamos redes sociales, sino en escenarios asociados a aplicaciones de gestión en los que queremos reforzar la transparencia. Imaginemos un sistema de reclamaciones, ¿no sería deseable publicar el estado de un banco o de una papelera tal y como lo suben los ciudadanos y antes de su reparación? ¿no querríamos que esto se publicara de forma anónima?
Si pensamos un instante sobre ello, seguro que percibimos que existen una gran variedad de potenciales problemas y gestionarlos de forma manual conduciría, de forma casi segura, a que no se publique ninguna imagen en absoluto. Aquí es donde la IA es útil, podriamos eliminar imagenes pornográficas, o borrar o pixelar caras de ciudadanos anónimos.
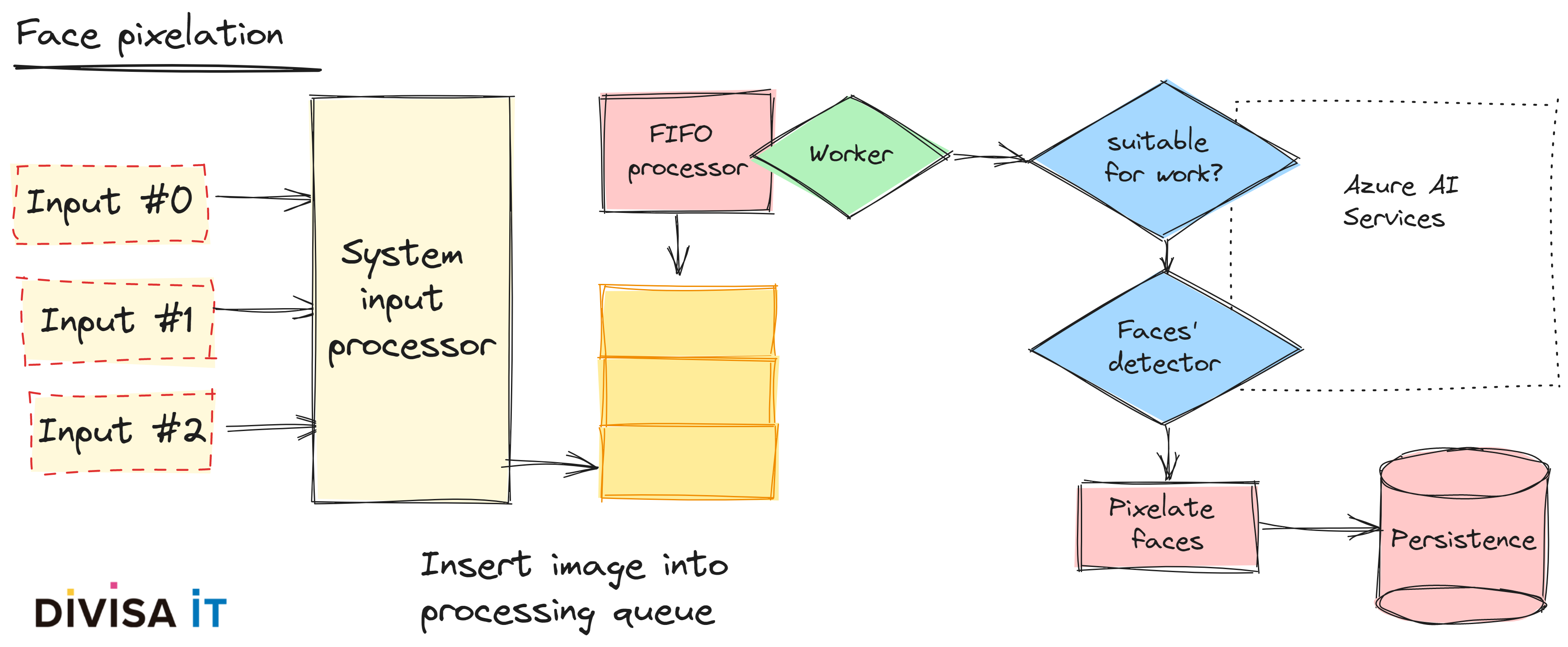
Traducido a la visión desde la ingeniería, que es mi preocupación principal, ¿qué deberíamos tener en cuenta?
Cuando desarrollamos aplicaciones existen una serie de problemas típicos a resolver, uno de ellos es si la aplicación va a soportar sólo un único canal de entrada o, si bien, va a ver varios. Este último caso es, ciertamente, problemático, puesto que cada uno de los canales va a imponernos una forma de realizar el diálogo con el usuario.
Analizando un escenario sencillo en el que utilicemos un formulario web, tendremos con seguridad una serie de opciones de entrada, probablemente un selector y con seguridad un área de texto. Si avanzamos un poquito más, imaginemos ahora que el canal de entrada es el correo electrónico o WhatsApp. El correo no permite un diálogo y el segundo, aun cuando podemos crear un bot, la verdad es que la experiencia de usuario se ve algo resentida ¡mantengamoslo simple!
Así pues, ¿qué podemos hacer? ¿evitar estos canales? ¿es posible, o deseable? Si la respuesta es que los necesitamos, ¿es asumible una revisión manual? Probalmente la respuesta sea que nuestro cliente lo necesita, pero de forma automática. Nuevamnete la IA podría ayudarnos, permitiendonos rellenar la información que nos falta utilizando algoritmos perfectamente conocidos como Naive-Bayes, suponiendo que tengamos suficientes datos para realizar el entrenamiento.
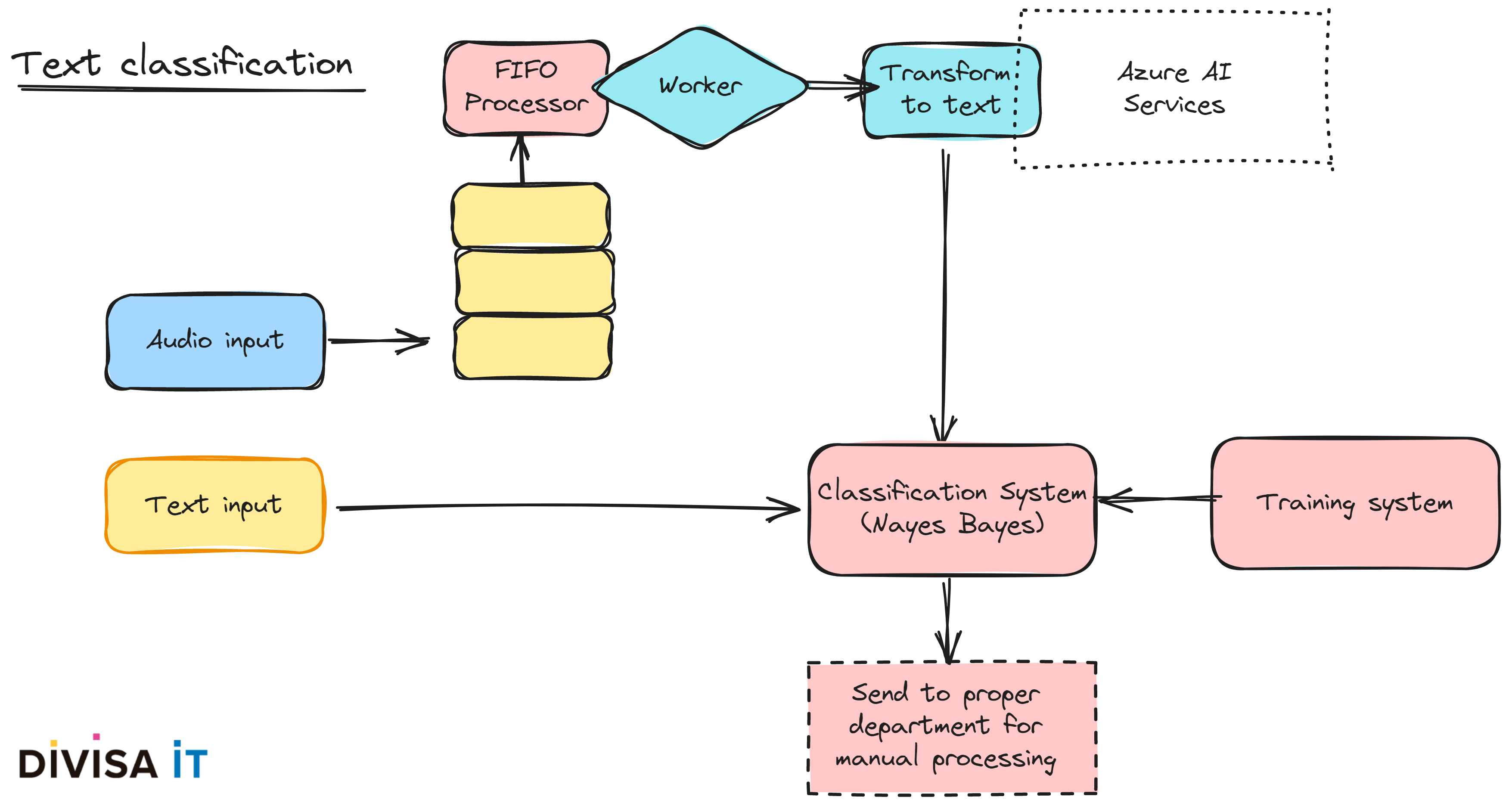
Siguiendo con el planteamiento anterior, ¿qué supone esto desde el punto de vista de una solución de ingeniería?, ¿qué debemos tener en cuenta?
Desde que consigo recordar la idea de introducir agentes que faciliten la localización de recuperación de información - búsqueda - en un sistema web ha sido una constante. La solución típia pasaba por la creación de árboles de decisión, lo cual introducía un problema desde el punto de vista de la experiencia de usuario, el diálogo estaba bastante estereotipado y, por tanto, conducía a un diálogo no demasiado natural.
La aparición de las soluciones LLM, como ChatGPT, sin duda ha ofrecido nuevos mecanismos que permiten resolver este problema. De hecho, parece tan humano que incluso miente, aunque en este caso hablamos de alucinaciones.
Ahora bien, pensemos en como aplicar esto en la instalación de uno de nuestros clientes. A fin de cuentas lo que queremos es buscar en su base de datos, en su información y que las respuestas sean buenas y naturales. Pero, ¿queremos hechos o respuestas imaginativas o incluso falsas? ¿Vamos a tolerar los problemas que una respuesta imaginativa a una petición podría provocar? Imaginemos un escenario en el que emitimos una respuesta incorrecta a una pregunta sobre plazos para la presentación de una solicitud o no proporocionar todos los detalles sobre la información que debemos aportar al solicitar una subvención.
Seguramente un entrenamiento personalizado podría ayudarnos a minimizar estos problemas. Pero, como me gusta decir, la ingeniería va también sobre la gestión de la escasez. A veces no hay presupuesto suficiente, otras no hay tiempo y en muchas otras no disponemos ni de una cosa ni de la otra.
Así pues, ¿qué solución podemos usar que nos permita manejar de forma eficaz esta escasez? ¿podríamos utilizar una LLM pre entrenada como ChatGPT? Logicamente si, pero debemos utilizar aproximaciones alternativas a la estándar.
Analicemoslo con un poco más de detalle, para ello primero que debemos hacer es preguntarnos que es lo que queremos que haga nuestro agente o, más bien, que problema estamos intentando resolver.
Las respuestas a estas cuestiones definirán como va a funcionar nuestro sistema. Pero, en cualquier caso, típicamente nos encontraremos con contextos complejos n-dimensionales y que, a su vez, mantendrán relaciones m-n con nuestra base de datos de preguntas. Por tanto y si nos planteamos esta cuestión desde el punto de vista de una solución de ingeniería, tendremos que abordar los siguientes problemas.
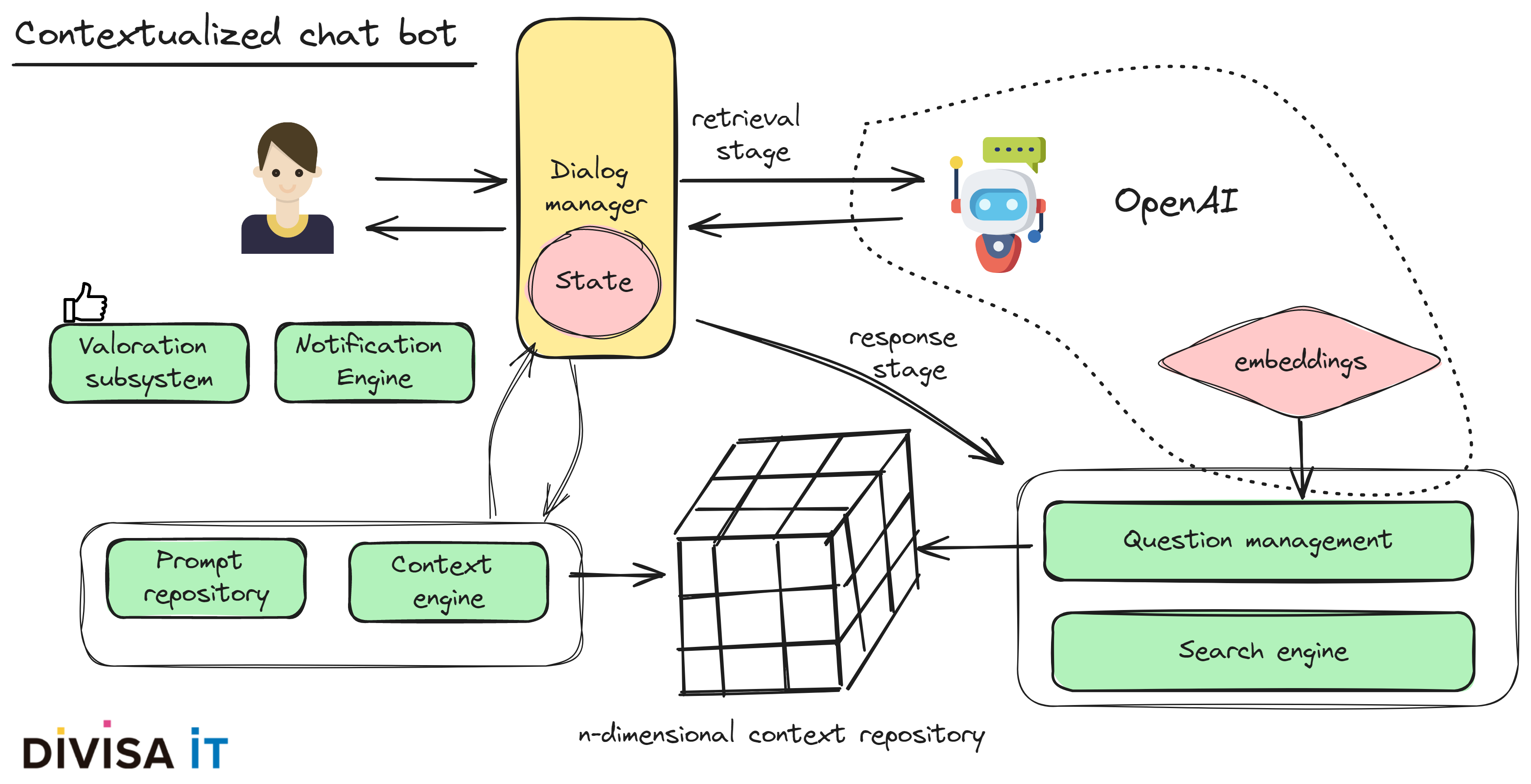
Tal y como he tratado de mostrar, utilizar soluciones que empleen la IA nos podría ayudar a obtener mejores resultados, pero ello no niega que empleamos una arquitectura de software adecuada y buenas prácticas de ingeniería.
 David Rodríguez AlfayateDirector de Tecnología, Productos y proyectos especiales
David Rodríguez AlfayateDirector de Tecnología, Productos y proyectos especiales