Cargando...
La innovación, nuestra razón de ser
En mi opinión, uno de los problemas de los que más frecuentemente nos olvidamos cuando desarrollamos aplicaciones es de que éstas sean capaces de funcionar sin conexión. Estamos tan acostumbrados a la programación de aplicaciones web, que nos hemos olvidado de considerar aquellos casos en los que el servidor no se encuentra disponible, o la conexión no es tan buena como debería ser. A decir verdad, estos problemas no son tan importantes cuando nuestra aplicación es sólo web, pero sí que deberíamos preguntarnos que pasa cuando lo que hemos desarrollado es, en realidad, una PWA, una app híbrida o incluso una aplicación de escritorio basada en Electron.
Por tanto, si nos encontramos en un escenario como estos, deberíamos tener en cuenta como desarrollarlo o qué problemas podríamos encontrar. Una primera aproximación podría ser reducir el problema al típico de productor-consumidor, sin embargo, la realidad es que lo que tenemos es un caso de sincronización en el que deberíamos tener en cuenta otras consideraciones como, por ejemplo, ¿hay un único origen de verdad? ¿pueden modificar distintos usuarios finales el mismo dato?
Por otra parte, cómo sabéis, estos procesos de sincronización o de productor-consumidor no deberían realizarse en el mismo "hilo" que pinta. No queremos que por "sincronizar" cada poco tiempo estemos afectando a como pintamos. Este problema es bastante conocido en entornos como el desarrollo de apps móviles nativas, sin embargo, cuando nuestro entorno de ejecución es el navegador y el lenguaje de programación es JavaScript las cosas no parecen tan fáciles.
A lo largo de este post, intentaré daros información de como podríamos resolver este problema. Si te da pereza seguir leyendo puedes ir a este repositorio en Github, donde puedes encontrar un ejemplo, si quieres saber algo más te invito a que continues leyendo.
donde puedes encontrar un ejemplo, si quieres saber algo más te invito a que continues leyendo.
Pensad en el problema como un escenario en el que:
En una solución típica, podríamos enviar datos al servidor e implementar cualquier tecnología que queramos para sincronizar: long polling, web sockets, etc. Pero ¿qué pasa si el entorno es móvil?, ¿si tenemos una conexión a internet lenta o, si incluso, no tenemos conexión? ¿estamos preocupados de la experiencia de usuario final?
Si tu respuesta es afirmativa, desde mi punto de vista la mejora opción para resolver el problema es partir del supuesto de que no hay servidor. ¡Dejadme explicaroslo! Necesitáis almacenar información, leerla, pero desde el punto de vista de vuestra lógica de aplicación no deberíais preocuparos de la sincronización con el servidor. Si conocéis Redux deberíais tener una idea clara de lo que son los efectos colaterales, si no lo tenéis muy claro o no os apasiona demasiada, pensad en ello como:
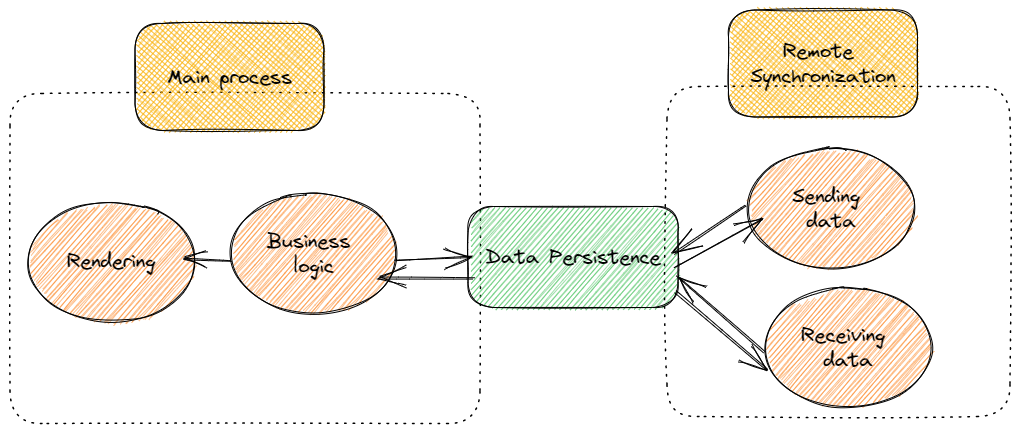
Por tanto, para dar una solución desde el punto de vista de frontend deberíamos enfocarnos en:
..Lógicamente, la lógica de frontend esta fuera del alcance de este post. ¡Es vuestra lógica!, así que lo que me voy a centrar en los puntos siguientes es en como plantear esa persistencia, y como procesar la cola utilizando Web Workers. Tened en cuenta que en un entorno real hay muchas más complejidades, como, por ejemplo, seguridad, colisión de datos – actualización de la misma información en distintas aplicaciones por usuarios distintos, etc. -, aspectos éstos que no voy a cubrir en este ejemplo.
Tal y como os comentaba antes, la solución de persistencia pasa por IndexedDB. Pero, la verdad, es que este API es un poco de bajo nivel, un poco complejo, así que si fuera uno de vosotros optaría por utilizar algunas APIS de alto nivel como Dexie. Esta es la aproximación que he seguido en el repo que os he compartido.
Desde mi punto de vista una de las principales ventajas del almacenamiento NoSQL – como IndexedDB – es que no tenemos que ser exactamente conscientes de los datos que tenemos que leer o almacenar, sino solo disponer de algún mecanismo que nos permita leer y escribir y que tenga la suficiente información como para poder hacer lo que necesitamos y, ¿eso qué es?
Veámoslo en detalle en los siguientes apartados
Básicamente necesitamos crear una Base de datos que no sea exactamente consciente de lo que vamos a guardar, pero que nos permita realizar las operaciones CRUD básicas y aquellas relacionadas con la gestión de la cola y los identificadores universales. Para ello, nos basta simplemente un poco de TypeScript que extienda el modelo de Dexie. En concreto,
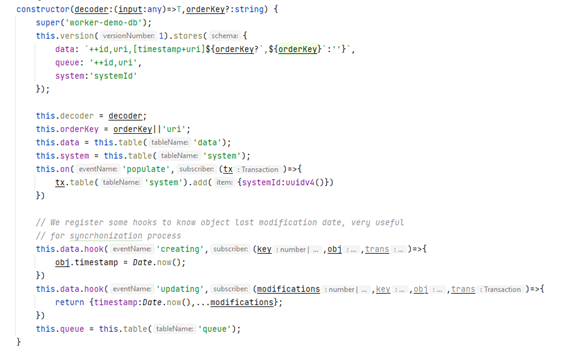
Como podéis ver en el constructor se crean tres tablas – fijaos que en IndexedDB sólo especificamos índices, no la estructura real de la tabla -.
Adicionalmente, hay algunos hooks que nos permiten introducir el timestamp – fecha de última cambio – siempre que creamos o actualizamos una entidad.
Un momento, si os fijáis no estoy hablando de datos reales, sino de metadatos que tienen cierta información. Bueno, en realidad, es la magia de TypeScript e IndexedDB, no hace falta que tengamos nuestro modelo completamente definido, pero si debemos asegurarnos de que tenemos lo mínimo para que sea reutilizable y aprovechar las capacidades de herencia que nos ofrece el lenguaje
![]()
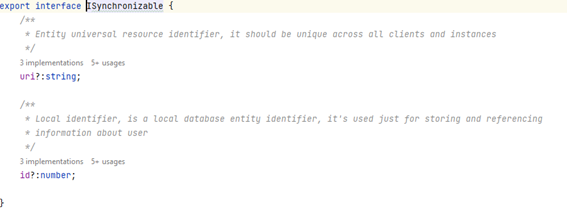
Para convertir el objeto almacenado al modelo lógico real (importante si tenéis getter, setter o funciones personalizadas, vamos lo que debe ser un modelo) debemos tener decodificadores que en mi ejemplo se pasan como parámetros al constructor y se emplearan cuando leamos los datos.
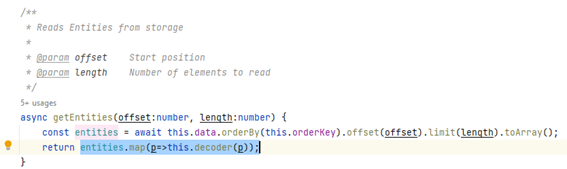
Os podríais preguntar como manejamos la cola. En realidad, no es algo muy complejo y sólo tenemos que tenerlo en cuenta en los procesos de creación, actualización y borrado.

Sin duda, podríamos haber utilizado hooks para rellenar la cola, pero queremos evitar bucles. No queremos que la sincronización remota introduzca nuevamente algo en la cola, ¿no? Obviamente, existen mecanismos para evitarlo, pero introducirían muchas condiciones de contorno que harían que nuestro código no fuera lo suficiente limpio ni legible.
Así cuándo queramos sincronizar nuestros datos con la información remota, sólo tenemos que acceder a la base de datos y aquellos métodos que se orienten al proceso de sincronización
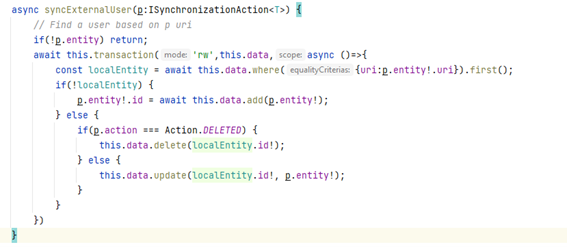
En el ejemplo que os pegado, este código permite aplicar una acción de sincronización en nuestra base de datos, eliminando aquellas entradas, creando o actualizando las necesarias. Notad que siempre estoy utilizando el Identificador Universal de la Entidad en lugar del id local.
El procesamiento de la cola es un poquito más complicado, tendremos que trabajar con promesas (enviar un dato al servidor, típicamente, implicará una petición fetch). En el ejemplo que de mi repo, las operaciones se ejecutan, además, de forma secuencial y tenenmos que garantizarnos que ante el éxito se elimine la entrada de la cola (queremos evitar el doble procesamiento)

Como podéis ver, nos limitamos a leer la cola, obtener la información que queremos enviar, enviarla y si el proceso termina bien eliminamos la entrada de la cola. Si me permitís, una pequeña aclaración, en las operaciones siempre se enviará el timestamp – esa es la magia de JavaScript – puesto que lo almacenamos junto con la tabla de datos, de esta forma siempre podríamos implementar en el servidor mecanismos de comprobación adicional orientados a evitar modificaciones repetidas.
Queremos que sea fácil y reutilizable. Puesto que en el ejemplo estoy utilizando REACT me voy a centrar en proporcionar el acceso a la Base de datos a través del contexto y custom hooks.
El contexto nos permite esconder la creación de la base de datos utilizando un componente que realiza toda la parte "compleja", almacenándola en un estado y disponibilizándola a lo largo de nuestra aplicación.

Un caso de uso de este contexto sería algo tan simple como:

Una vez creado y para acceder a las operaciones reales (leer, borrar, actualizar, crear) podríamos recuperarlo y manipularlo de forma directa. No obstante, no es una aproximación que nos permita garantizar la reusabilidad de nuestro código. Así que desde el punto de vista de REACT lo más limpio sería crear un custom hook, que nos permita aislar toda la complejidad de una forma lo más simple posible
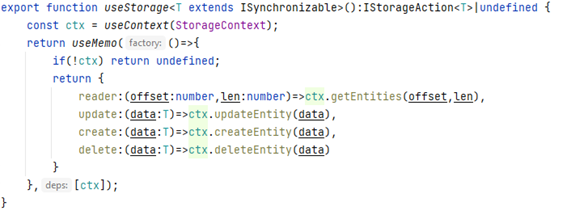
Como podéis ver, estoy usando de forma profusa los interfaces que he definido en TypeScript garantizando así un código bien definido y correctamente reutilizable. El uso del hook useMemo se orienta a permitir que el resultado de nuestro hook se pueda utilizar dentro de un useEffect sin problemas colaterales.
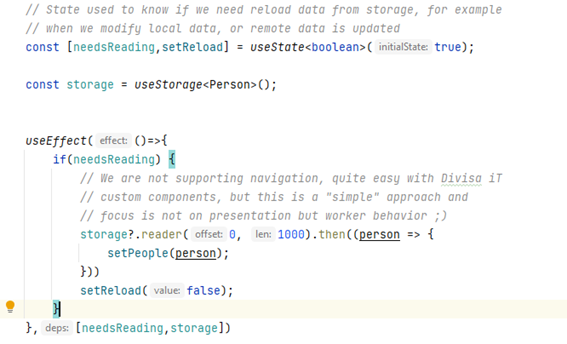
Para realizar estas tareas, voy a utilizar – como os decía antes – Web Workers, si no tenéis muy claro lo que son, simplemente pensad en ellos como procesos independientes que se ejecutan en vuestro navegador y que no afectan ni al proceso de pintado ni a la lógica de negocio. Si bien podría plantearse un único worker, considero que es mejor crear dos puesto que tienen que hacer, en realidad, cosas ligeramente distintas.
Más allá de enviar y recibir datos tenemos otras necesidades que cubrir como el sistema de logs, o como conectar los workers a nuestra aplicación de una forma directa.
Pensad que es un proceso repetitivo que lo tenemos que hacer mientras nuestra aplicación este viva, para ello el uso de timeouts es más que suficiente y la única "complejidad" viene de utilizar un worker.
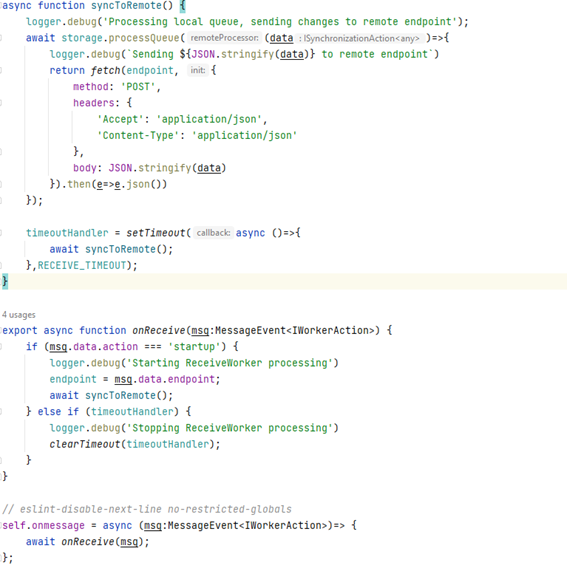
El código es bastante sencillito, el método syncToRemote se limita a leer la cola y enviar los datos al servidor mediante el API fetch.
Lo primero que deberíamos preguntarnos es si queremos que el servidor nos envíe todos los datos en cada petición de sincronización. Estoy bastante convencido de que vuestra respuesta será negativa. Siendo así, que debemos hacer, como debemos diseñar nuestro protocolo de comunicación para tener esto en cuenta. Básicamente, algo como lo que os pinto a continuación:
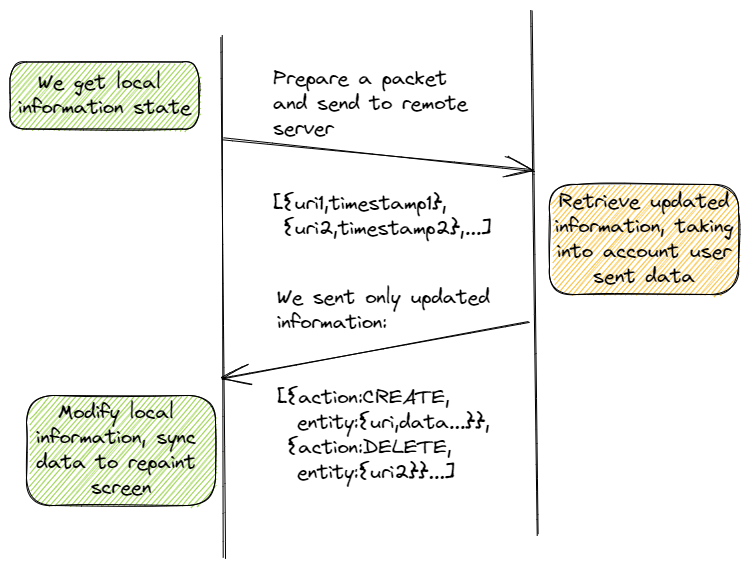
Podéis ver que,
En el repo podéis ver un código de ejemplo como el siguiente
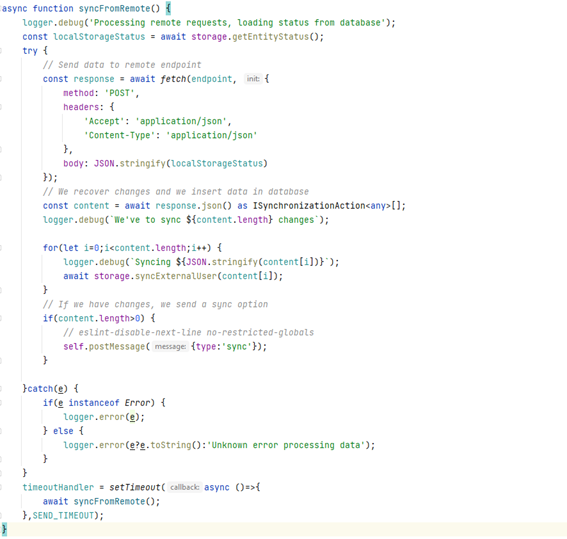
La función en el storage que nos permite recuperar el estado se llama getEntityStatus y se limita a proporcionarnos lo que tenemos
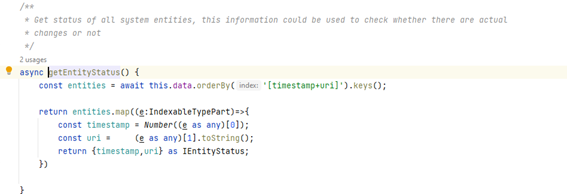
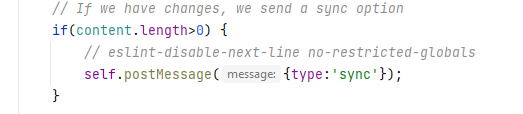
Con los datos recibidos ya nos limitamos a sincronizar la información y utilizar un postMessage especial para informar a nuestra lógica de aplicación de la existencia de cambios que deberían mostrarse a los usuarios.
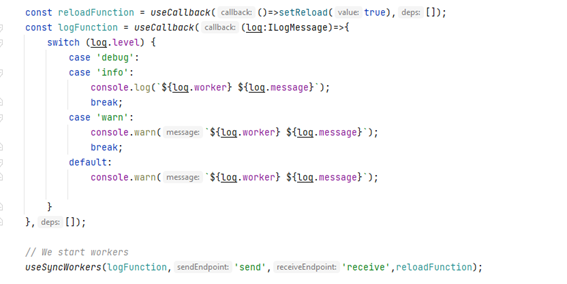
Para utilizar estos workers, mi aproximación es, en aras de una mayor reusabilidad del código, utilizar custom hooks.

El hook crea los workers – a través de una función, pero eso es por un tema de testing -, implementando todos los procesos de inicialización y terminación y recibiendo de los workers los datos de log y cuando debemos sincronizar los datos.
El uso del hook es extremadamente sencillo, sólo deberíamos utilizarlo en el lugar adecuado con los parámetros de configuración adecuados.
La verdad es que siempre que desarrollemos una aplicación deberíamos tener algún mecanismo de log, no deberíamos pensar en la consola, no nos ayuda a saber que les pasa a los usuarios. Un sistema de logging podría implicar enviar datos a un servidor remoto, en un orden concreto, etc. ¿un sistema de colas como el comentado?
En cualquier caso, cuando utilicemos Web Workers si queremos imprimir logs, deberíamos tener en cuenta estos problemas, así que una buena aproximación podría ser crear un sistema de logs basado en eventos (postMessage), tal y como os muestro a continuación
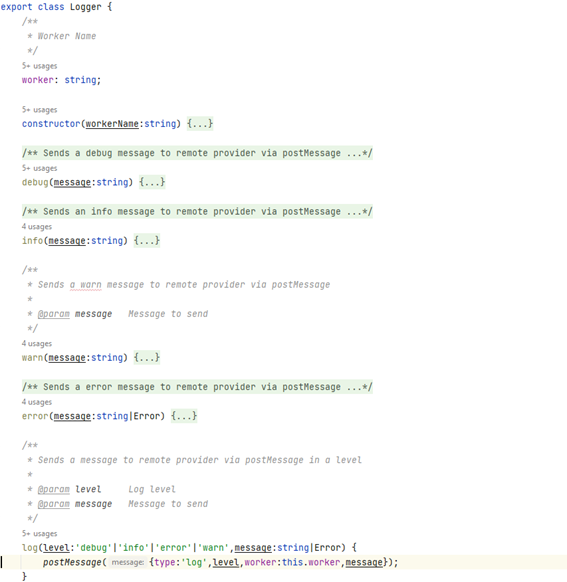
En el código de ejemplo del repo, he utilizado simplemente un log en consola, pero confío en que la idea general, os podría proporcionar una mejor comprensión de cómo hacerlo adecuadamente.
Una vez que la infraestructura está creada podemos utilizarla desde nuestra aplicación, en esta imagen os muestro la aplicación de ejemplo que podéis descargar del repo y los errores relacionados con los endpoints remotos no disponibles
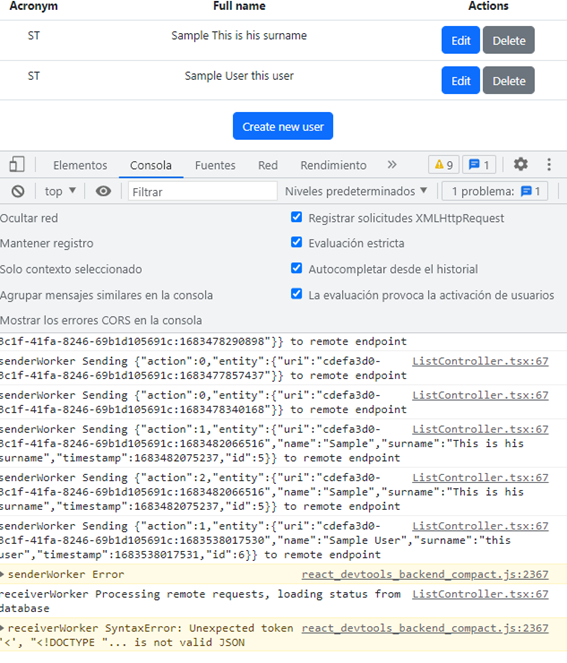
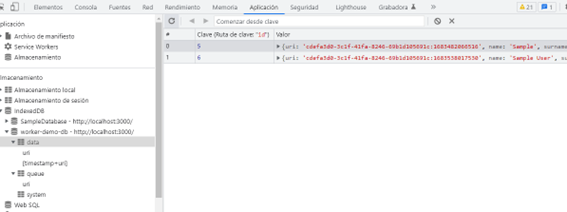
Si veis la base de datos IndexedDB podéis ver información interesante sobre como se almacenan los datos y como se emplean los índices
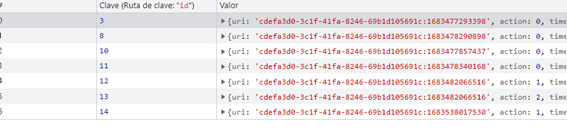
O, incluso, la cola
Además de daros información de como los workers podrían utilizarse para realizar tareas de sincronización, creo que también podéis encontrar información interesante en el repo, por ejemplo, como debemos aislar modelos, lógica de vista y presentación, etc.
 David Rodríguez AlfayateDirector de Tecnología, Productos y proyectos especiales
David Rodríguez AlfayateDirector de Tecnología, Productos y proyectos especiales